
You have an A/B testing tool, a well-researched hypothesis and a winning test with 95% confidence. The next step is to declare the winner and push it live, right?
Not so fast.
There are factors threatening the validity of your test, without you even realizing it. If they go unrecognized, you risk making decisions based on bad data.
Table of contents
What Are Validity Threats?
Validity threats are factors that can threaten the validity of your A/B test results.
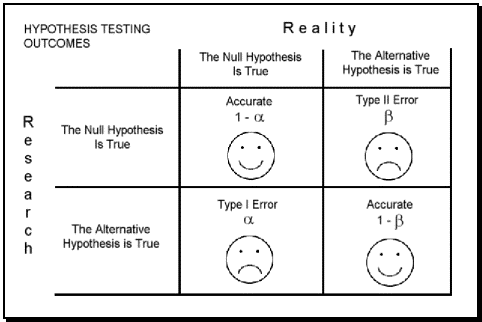
There are two types of errors that occur in statistics, Type I and Type II. Type I errors occur when you find a difference or correlation when one doesn’t exist. Type II errors occur when you find no difference or correlation when one does exist.
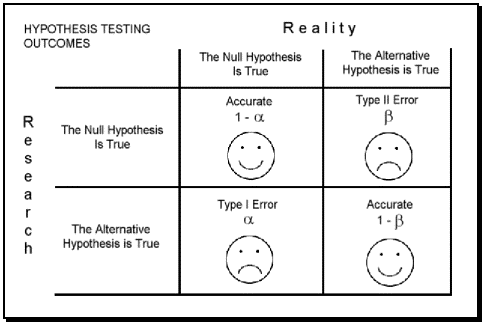
Validity threats make these errors more likely.
In order to understand validity threats, you must first understand the different types of validity. Of course, there are many, but the three most common (and relevant) types of validity for conversion optimization are: internal validity, external validity, and ecological validity.
If it can be proven that the cause comes before the effect and the two are related, it’s internally valid. If the results can be generalized beyond that individual test, it’s externally valid.
Often, internal and external validity work against each other. Efforts to make a test internally valid can limit your ability to generalize the results beyond that individual test.
Ecological validity looks how applicable the results are in the real world. Many formal, laboratory-based tests are criticized for not being ecologically valid because they are conducted in artificially controlled environments and conditions.
Yeah, But That Doesn’t Affect Me, Right?
Of course it affects you. Validity threats affect anyone who runs a test, whether they realize it or not. Just because test results look conclusive, doesn’t mean they are.
For example, Copy Hackers ran a test on one of their home page a couple of years ago. They decided to optimize this section of their page for “Increase Your Conversion Rate Today” clicks…

During the first two days, the results were very up and down. After just six days, their testing tool declared a winner with 95% confidence. Since it hadn’t been a full week, they let the test run for another day. After a week, the tool declared a 23.8% lift with 99.6% confidence.
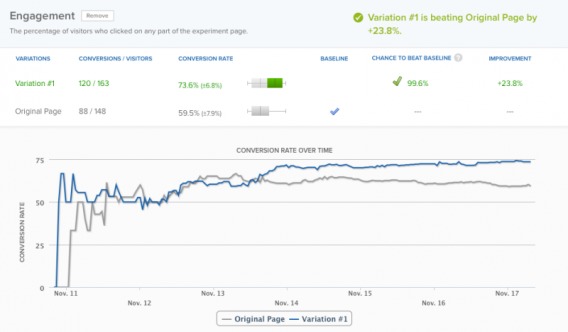
Seems like a conclusive win, right? Well, it was actually an A/A testing, meaning both the control and the treatment were exactly the same.
Testing tools cannot account for all validity threats for you, which means you could be drawing insights and basing future tests on inconclusive or invalid results. These types of results due to validity threats can, and do, happen to you.
(You just don’t know it, yet.)
How Can I Eliminate Validity Threats?
The simple answer is that you can’t completely eliminate validity threats. They do and will always exist. It’s not about eliminating validity threats completely, it’s about managing and minimizing them.
As Angie Schottmuller explains in detail, it’s important to recognize validity threats prior to testing…

Angie Schottmuller, Growth Marketing Expert:
“Minimizing data ‘pollutants’ to optimize integrity is the hard part. Brainstorming and reviewing a list of any technical and environmental factors/variables that could potentially corrupt test validity is done up-front.
Pro Tip: Do this with your campaign team (e.g. PPC, SEO, IT, brand, etc.) whenever possible to best inventory and understand test risks and gain all-around support for testing. The team will be less likely to implement a change (‘test threat’) if they were involved up front, and it provides more eyes to monitor for unexpected ‘pollutants’ like competitor promotions, direct mail campaigns, or even regional weather factors.
I try to ensure the team documents in detail all approved or unexpected changes during the test. (e.g. PPC campaign management for excluding/adding keywords or ad placement.) Quality and timely team communication regarding changes is imperative, since some updates might void test validity. It’s better to learn quick and adapt than to proceed ignorant and foolish.
Note: After inventorying test threat variables it is possible to conclude that a planned test would produce (invalid) inconclusive results. Concurrent campaigns, technical upgrades, holidays, or other significant events might present too much risk. It’s best to recognize this BEFORE testing. Minimally, leverage it as an opportunity to show the inherent risk in testing and the need for iterative tests and multiple approaches (quantitative and qualitative) to validate a hypothesis.”
There is always risk in A/B testing, so before you test, go through these steps:
- With the help of your entire team, inventory all of the threats.
- Make your entire team aware of the test so that they do not create additional threats.
- If the list of threats is too long, postpone the test.
Why waste the testing traffic when the risk of invalid results is so high? It just doesn’t make sense. Instead, wait until you can run the test and gather conclusive insights.
Remember, as an optimizer, your primary goal is discovering conclusive insights that can be applied to all areas of your business, not simply winning individual tests.
Angie Schottmuller, Growth Marketing Expert:
“‘With great [test significance] power comes great [validity risk] responsibility.’
– Benjamin Parker (Spider-Man’s Uncle), a / Adapted by @aschottmuller
Balance accordingly and keep focus on learning confident insights, not simply achieving a desired single-test result. ”
8 Common Validity Threats Secretly Sabotaging Your A/B Tests
Validity threats are widespread and come in many different forms, making them difficult to recognize. There are, however, some common validity threats that you’re more likely to run into than others.
1. Revenue Tracking
Inserting the testing tool javascript snippet is easy. But if you run an eCommerce site, you also need to implement revenue tracking for the testing tool. This is where things often go wrong.
Leho Kraav, a Senior Conversion Analyst at CXL had this to say about revenue tracking implementation:

Leho Kraav, CXL:
“The main mistakes I see are…
1. Not having multiple tools counting revenue / transactions and reporting results in a format that even your mother should be able to understand whether things add up. Any tool can potentially mess something up, so you need backup. Basic combination: sales backend, Google Analytics e-commerce, and Optimizely. Main problem: understandable, consistent cross-tool reporting.
2. Messing up tracking tag firing when using multiple payment gateways. Examples: gateways send people to different thank you pages where different tags fire, bad return from gateway IPN handling in the code, etc.
3. Depending on the complexity of the checkout process of your app, it’s possible to accidentally fire revenue tracking multiple times. Depending on the tool, this can artificially inflate your revenue numbers. Once again, using multiple tools is helpful to verify any one tool’s periodic revenue report.
4. Not paying attention to the specific format tools want the transaction value in. Some want cent values, some dollar values. Fortunately, this is easy to notice unless you’re completely not paying attention.”
How to manage it…
- Always integrate your testing tool with Google Analytics to see if the revenue numbers (mostly) match up.
- If you see huge discrepancies (2x differences are not uncommon), you have a problem. Stop the test immediately, fix the problem and restart the test.
2. Flicker Effect
The flicker effect is when your visitor briefly sees the control before the treatment loads. This can happen for various reasons, like…
- The asynchronous script your testing tool uses, which is designed to speed up load times, but comes with an unfortunate side effect.
- Your overall website load speed is slow.
- Your testing tool is loaded via Google Tag Manager instead of directly on the page and you don’t control the load order.
- Too many other scripts are loaded before your testing tool script.
- An element of your test triggers an action that disables or changes your testing tool code.
- Your testing tool code was added to the <body> on some pages and the <header> on others.
How to manage it…
- The goal is to reduce the flicker to 0.0001 seconds so that the human eye won’t detect it.
- Optimize your site for speed. (Here’s how to do that.)
- Simply try split URL testing instead.
- Remove your A/B testing tool script from Tag Manager.
3. Browser / Device Compatibility
Your treatments keep losing and you can’t figure out why. Provided that you’re actually testing the right stuff, the most common reason for failing tests is crappy code (i.e. variations don’t display / work properly in all browser versions and devices).
If it doesn’t work right on the browser / device combination your visitor is using, it will affect the validity of the test (i.e. non-working variations will lose).
This happens a lot when using the visual editor. (Unless you’re just doing copy changes, don’t ever use the visual editor.) The generated code is often terrible, and you might be altering elements you don’t mean to.
You can’t launch a test without doing proper quality assurance (QA). You need someone to put in the time to conduct cross-browser and cross-device testing for each variation before starting the experiment.
For example…
- Don’t just look at the treatment on the browser that you have on your computer. The treatment might be displaying incorrectly in IE9 and IE10, which you personally never use. Unfortunately, if 20% of your visitors use IE, that’s a problem.
- Similarly, you might test the treatment on an iPhone, but fail to notice that it’s all funky on Android.
How to manage it…
- Always conduct quality assurance for every device and every operating system.
- Run tests separately for each type of device. This way, you reduce the risks associated with cross-device pollution.
4. Sample Size
Essentially, a test doesn’t produce valid results when you reach 90% significance, you must continue the test until you’ve reached the necessary sample size as well. Peep has written on stopping A/B tests, which covers sample size in-depth. If you have a few minutes, I suggest reading it thoroughly.
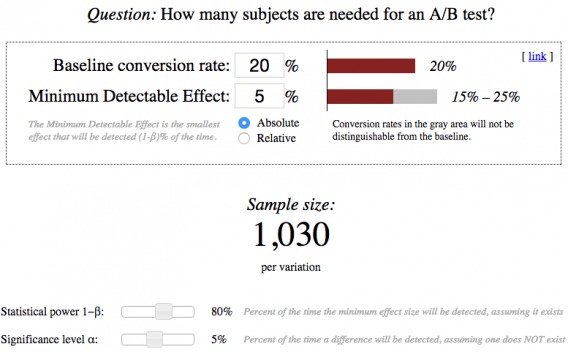
For example…
- If you run an A/A test (like Copy Hackers did), where both variations are exactly the same, you could see a temporary significant effect in your experiment… a false positive. Significance is not a stopping factor, sample size is.
- Data fishing is when you run a test multiple times and repeatedly reanalyze the data. Often, this happens as a result of confirmation bias. You’re “fishing” for an outcome. Unfortunately, by treating each test as though it’s independent, you’re likely to run into a false positive.
- Maturation also comes into play. The longer you run a test, the more validity threats you’re open to because there’s more opportunity for your sample to mature (i.e. change).
How to manage it…
- Stop your test when you have sampled the correct sample size. Use CXL’s AB test calculator.
- Take data fishing into account and adjust your significance level to compensate for the number of tests you’re running.
- Run tests for as long as necessary (i.e. until your sample size is reached) and not a moment longer. This will help avoid maturation as much as possible.
5. Selection Bias
Not only does your sample need to be large enough, but it needs to be representative of your entire audience, as well. Earlier this year, I wrote an article on sample pollution, which covers sampling a representative audience in detail.
Let’s say you have a low traffic site, and in order to run the experiment within a reasonable amount of time, you decide to acquire paid traffic. So you start a PPC campaign to drive paid traffic to the site. The test runs its course and you get a winner – 30% uplift!
You stop the PPC campaign and implement the winner, but you don’t see the 30% improvement in your sales. What gives? That is selection bias in action.
You assumed that your PPC traffic behaves the same way as the rest of your traffic, but it likely doesn’t.
Similarly, if you run a test using only your most loyal visitors or only women or only people who make over $75,000 a year, you don’t have a representative sample. That means your results cannot be generalized.
How to manage it…
- When testing, use a representative sample. Include traffic from all sources, every day of the week, both new and returning traffic, etc.
- Don’t acquire traffic from “unusual” sources.
6. Day of the Week & Time of Day
Your traffic behaves differently on a Saturday than it does on a Wednesday. Similarly, your traffic behaves differently at 1 p.m. than it does at 1 a.m.
For example…
- On Saturday evening, maybe your visitors view your site longer because of the extra free time a weekend allows.
- On Sunday night, maybe they bounce quickly because they’re parents who have to prepare for school the next morning.
- On Tuesday afternoon, you might see a spike in traffic as people take a late lunch and browse Twitter.
- On Thursday morning, maybe you see an increase in conversions because of your weekly newsletter.
On different days of the week and at different times of day, your traffic behaves differently. They are in different environments, different states of mind. When the context changes, so does their behavior.
If you ran a test from Monday to Friday, for example, you would have inconclusive results, even if you reached significance. What’s true for weekday traffic cannot be generalized to weekend traffic with complete accuracy.

How to manage it…
- Run tests for full week increments so that you include data from every day of the week and every time of day.
7. Season, Setting & Weather
Other external and seemingly irrelevant factors that affect the validity of your test include: the season, the setting visitors are in when they visit your site, the weather, and even the media.
For example…
- If you’re a blogger, the holiday season will likely result in a traffic decrease. If you’re an eCommerce site, it could very well be your most trafficked time of the year.
- If you’re a B2B product or service, you likely see more conversions during business hours, when your visitors are at the office and thinking about work.
- If you’re a B2C product or service, you likely see more conversions outside of business hours or around noon, when people are at home and thinking about their personal life.
- If there’s a major storm coming, you sell storm-proofing services, conversions are going to spike. That one’s obvious, but experts say they can predict how (and what) consumers will buy based on the weather with a startling amount of accuracy.
- In Seattle, the difference between one and three inches of rain has a major impact on what type of beer is purchase. In Los Angeles, the wind is what affects beer sales.
- If there’s a major news story, like an assassination or a missing plane or a group of rescued refugees, it can create a bias towards one of your variations that might not exist in two weeks or two months. Of course, it can also influence traffic and consumer interest.
- One of the biggest, most captivating news stories of our generation was the O.J. Simpson trial. When the trial was in session, the Infomercial Marketing Report newsletter reported a significant drop in sales because consumer attention was elsewhere.
How to manage it…
- If you run a test during a holiday season, know that the data you collect is only relevant to that season. Trying to apply the results of a test run in late December to January or February would be invalid.
- Look at your annual data and identify anomalies (in traffic and conversions). Do your beer sales spike every spring when it rains more often? Or in the fall when it’s more windy? Account for this when running your tests. The results of tests run during those periods cannot be generalized to other times of year with complete accuracy.
- Be aware of pop culture and the media. Document major news stories as they happen. If you see a major, unexpected spike, consider that it could be the result of the media coverage. Does the timing line up? Is it relevant to your site and audience?
8. Competitive & Internal Campaigns
As Angie mentioned above, your conversions could be increasing due to competitive and internal campaigns that are unrelated to your test.
For example…
- If your Marketing Manager is running a PPC campaign, you’ll see more traffic than usual. Likely, that traffic won’t behave as predictably as your usual traffic. The results of the PPC campaign could be influencing your A/B test, rending the results invalid.
- If your competitors are running a major campaign, your traffic could change as well. Perhaps you’ll see a drop as they head to your competitor’s site or perhaps you’ll see an increase as industry interest is sparked and consumers comparison shop.
How to manage it…
- Talk to your team before you run a test. Are there any marketing campaigns running during that time? Are there any technical upgrades occurring during that time? Take inventory before you run your tests. If you think the amount of threats is too high, hold off on the test.
Conclusion
Many A/B tests are plagued by validity threats, but most can be managed and eliminated. [Tweet It!]
The result? More accurate test results and more valuable insights.
Here’s the step-by-step process to removing the common validity threats…
- Always integrate your testing tool with Google Analytics to see if the revenue numbers (mostly) match up.
- Reduce the flicker to 0.0001 seconds so that the human eye won’t detect it. Optimize your site for speed, try split URL testing instead, remove your A/B testing tool script from Tag Manager.
- Always conduct quality assurance for every device and every operating system.
- Run tests separately for each type of device.
- Stop your test only when you have sampled the correct sample size.
- Take data fishing into account and adjust your significance level to compensate for the number of tests you’re running.
- Run tests for as long as necessary (i.e. until your sample size is reached) and not a moment longer.
- When testing, use a representative sample and don’t acquire traffic from “unusual” sources.
- Run tests for full week increments so that you include data from every day of the week and every time of day.
- If you run a test during a holiday season, know that the data you collect is only relevant to that season.
- Look at your annual data and identify anomalies (in traffic and conversions). Account for this when running your tests.
- Be aware of pop culture and the media. Document major news stories as they happen.
- Talk to your team before you run a test. Are there any marketing campaigns running during that time? Take inventory before you run your tests.
Related Posts
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-
A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there's…
-
A/B testing splits traffic 50/50 between a control and a variation. A/B split testing is…
-
You may be wondering, "why should I make my own visualization of my A/B test…




{kind=link}
“Run tests for as long as necessary (i.e. until your sample size is reached) and not a moment longer. This will help avoid maturation as much as possible.”
I’m sorry if this is a dumb question, but what does “maturation” mean in this context? I’m curious since I’d always figured running an A/B test for as long as possible would give the most accurate data, but apparently that’s not the case!
Since cookies get deleted (10-20% month or more), the longer you run the test, the higher the chance that somebody re-enters the test, but is bucketed to a different variation than before (see our article on Sample Pollution to learn more https://cxl.com/sample-pollution/). In most cases you don’t want to run a test longer than 4 full weeks (28 days).
It’s also worth noting that “Run tests for as long as necessary (i.e. until your sample size is reached) and not a moment longer. This will help avoid maturation as much as possible.” is to be paired with “Run tests for full week increments so that you include data from every day of the week and every time of day.”
Thanks for reading, Mikhail!
Hey Mikhail, thanks for the detailed information. “Run tests separately for each type of device” — I always do this during A/B testing so I can see if it works or not. It’s weighing in the options. I haven’t tried the other information you’ve mentioned so I’ll go check it when I’ll run a test soon.
Thanks for reading, Ethel.
Let me know how your tests go once you begin accounting for more validity threats!