
When you first start doing conversion optimization, you think that the biggest hurdles are technical things: running an a/b test the right way, collecting data correctly, QA’ing tests.
These things are all important, of course. But the solutions are fairly straightforward, and when you reach a certain level of experience and skill, they tend to be a given.
No, the biggest obstacle to a testing program – even a mature program – tends to be human error and cognitive bias.
No matter how data-driven you try to be, decisions are still always people-driven.
We’ve talked about cognitive biases that help you convert visitors, but what about the logical fallacies that prevent your program from operating at peak efficiency?
What Are Logical Fallacies?
Logical fallacies are arguments used in rhetorics that, despite being incorrect, are used to support the logic behind your argument or undermine the validity or soundness or another person’s argument.

Whether in the boardroom or your own mind, they can inhibit you from making clear and accurate decisions.
Our friends at Amplitude wrote a great post a while ago that outline fallacies that ruin your analytics, and it got me thinking about all the ways fallacies can diminish growth in general. This article will outline some of the most potent and dangerous logical fallacies we see time and time again. Learn them and mitigate their effects.
Note: this list only a touches on a few of the common ones. You can find many more here.
1. Hasty Generalization
A Hasty Generalization is an informal fallacy where you base decisions on insufficient evidence. Basically, you make a hasty conclusion without considering all variables – usually this is based on a small sample size and impatience.
Wikipedia gives the following example: “if a person travels through a town for the first time and sees 10 people, all of them children, they may erroneously conclude that there are no adult residents in the town.”
If you’ve read a blog post on A/B testing before, this already sounds familiar: don’t stop tests early. It’s sin #1 in A/B testing.T
This is where you may implement a test, and in some crazy circumstance, the results are incredibly lopsided. It seems obvious that variation B is getting its butt kicked. But if you “keep calm and test on,” you’ll notice that the trends even out and Variation B may even end up winning.

You may have heard this as the Law of Small Numbers, where one generalizes from a small number of data points.
This is obviously dangerous when it comes to A/B testing, but it can also sway other decisions in optimization. For example, in pursuit of qualitative research, you may collect 1000 answers from an on-site survey.
It takes a long time to read through all the answers, though, and 12 out of the first 18 said something about shipping concerns. With this limited sample, you’re likely to prioritize shipping as a problem area, even though the rest of the responses may well render this a minor issue – worthy of consideration, but not prioritization.
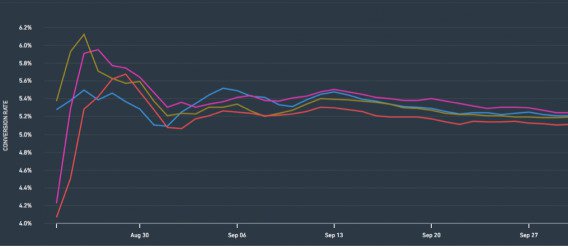
Bottom line: realize small datasets can be deceiving. Extreme trends at the beginning tend to balance themselves out over time, so be patient and run your tests correctly. As Peep once said, “You can’t test faster just because you/your boss/VCs want to move faster – that’s not how math works.”
Related fallacy: Slothful induction. That’s when you never deliver the rightful conclusion to a dataset, no matter how strong the data/trend. If you run a test well, and you have a winner, take the win and move on.
2. Appeal to Authority
“Fools admire everything in an author of reputation.”
― Voltaire, Candide
An Appeal to Authority is when, in the face of conflicting evidence, one summons the opinion of an ‘expert’ to solidify their argument.
According to Carl Sagan, “One of the great commandments of science is, ‘Mistrust arguments from authority.’…Too many such arguments have proved too painfully wrong. Authorities must prove their contentions like everybody else.”
So basically, when you’re prioritizing hypotheses and your best case argument is that “Neil Patel said testing fonts matters most,” you might want to look into a new career path.
I’m joking, of course, but there are a few very real problems with putting too much faith in gurus:
- Your website is contextual. The experiences of one expert may conflict with another, and you may derive zero value from any of their tactics.
- It’s easy for people to “play a doctor online.” By that I mean give someone a copy of You Should Test That!, an internet connection, WordPress, and through some magic alchemy, the world might welcome a new conversion rate optimization blogger. There’s lots of good info out there, but just be careful where you get your advice.
- Being swayed by authority implicitly limits the scope of your testing program by inhibiting ‘discovery.’ For a good read on how authority can limit efficiency, read this article on Quantam Team Management.

Another common iteration where you’ll see this logical fallacy is when someone brings up a large company as a golden example.
In the conversion optimization world, you’ll often hear Amazon, Airbnb, or Facebook invoked as someone to copy “because obviously they’ve tested it.” However, this appeal to authority is really used in every realm. Take this example from a Wordstream post:

As the author put it, “Just because eBay is a big company with a big marketing budget doesn’t mean that whoever’s in charge of their PPC knows what they’re doing. Big companies – whole empires even! – fail all the time. The history of the world is a catalog of failures. Authority doesn’t equal competence.”
Bottom line: don’t rule out experts – they have experience and therefore their heuristics tend to be more reliable. But when prioritizing tests or making decisions, an appeal to authority by itself is not a valid argument. It limits the scope of your thinking and sways the conversation to the status quo.
Which leads in nicely to the next fallacy…
3. Appeal to Tradition
The Appeal to Tradition, also known as “argumentum ad antiquitam,” is a fallacy where an idea is assumed to be correct because it is correlated with some past or present tradition. It essentially says, “this is right because we’ve always done it this way.
Changingminds.org puts it in a rather scary way, saying Appeal to Tradition is “where people do it without thinking and defend it simply because it now is a part of the woodwork. Familiarity breeds both ignorance of the true value of something and a reluctance to give up the ‘tried and true’.”
No doubt you’ve experienced this argument in your life, and if you haven’t experienced this at work: you’re lucky. Many company cultures are mired in allegiance to tradition and are hesitant to try new things – which is the antithesis of a culture of experimentation.
As Logically Fallacious put it, “If it weren’t for the creativity of our ancestors, we would have no traditions. Be creative and start your own traditions that somehow make the world a better place.”
I like it. Let’s create a tradition of experimentation.
Bottom line: while it may be true that your company has a tradition of success, it’s not due to the tradition itself. Therefore, “because it’s always been done this way,” isn’t a valid argument (in itself) for continuing to do it that way. Build a culture of experimentation and value discovery instead of tradition.
Related fallacy: Appeal to Novelty. This is the opposite, where things are deemed to be improved simply on the basis that they are new. In optimization, this often comes in the form of spaghetti testing, or testing random things just to introduce novelty. Again, novelty isn’t bad, but it can’t form the basis of judgement on its own.
4. Post hoc ergo propter hoc
Post hoc ergo propter hoc, or “after this, therefore, because of this,” is a post hoc fallacy that establishes causation where there is only correlation.
If you’ve ever read ’Candide’ by Voltaire, you’ll remember the eminent professor Pangloss – the philosopher who believed that everything was as good as it could be because “all is for the best” in the “best of all possible worlds.”
A quote from the book describes this post hoc fallacy perfectly:
“It is demonstrable that things cannot be otherwise than as they are; for as all things have been created for some end, they must necessarily be created for the best end. Observe, for instance, the nose is formed for spectacles, therefore we wear spectacles.”
As does this scene from The West Wing:
Just because one action precedes another does not mean there is a causal link.
Correlative metrics are a great starting point for finding optimization opportunities, but they need to be investigated. For instance, if you find visitors who watched a 30 second video convert better than those who don’t, it may be that the video helped assist the conversion – but it may be something else entirely.
So you run controlled experiments – A/B/n tests – to make causal inferences.
As Ben Yoskovitz, co-author of Lean Analytics, wrote:
 Ben Yoskovitz:
Ben Yoskovitz:
“You prove causality by finding a correlation, then running experiments where you control the other variables and measure the difference. It’s hard to do, but causality is really an analytics superpower–it gives you the power to hack the future.”
That’s why, while cohorts and longitudinal analysis can certainly give us some insight on the trends of our company, we don’t rely on them as an indicator of causation. If you implement a new value proposition on May 1st, and on June 1st you notice that conversions have dropped 15%, you can’t assume the value proposition caused that.
I saw Steven Levitt, co-author of Freakonomics, speak this year, and he told a story that perfectly illustrated this delusion in a corporate context.
He was brought on as a consultant to analyze the effectiveness of the client’s advertising campaigns. They had been running newspaper ads in every geolocation right before major holidays – say Father’s day – and experiencing great success doing so.
Their conclusion, of course, was that the advertising caused the revenue spikes. As if by magic, after the ads went live, sales would spike. Post hoc ergo propter hoc.
Thing is, they never used a control.
Levitt proposed setting up a controlled experiment, complete with a randomized sample, where they advertised in some locations and didn’t in others.
The findings? The advertising simply made no difference at all.

Bottom line: correlation doesn’t imply causation. Just because visitors who do X convert Y times better, doesn’t mean X causes this. Just because you implement a change and see a result after time, doesn’t mean that change caused the result. The only cure for this is to run controlled experiments (and even then be wary, especially if you’re a highly seasonal business).
5. False Dilemma
A False Dilemma, maybe better known as a False Dichotomy, is “a situation in which only limited alternatives are considered, when in fact there is at least one additional option.”
You tend to see this, at least in rhetoric, as a political device. To prod you to their side, shifty leaders, writers, and orators will create a false dichotomy where the logic goes, “if you’re not on this side, you’re on that side.” “That side” tends to be pretty unsavory, so you’re forced into a position you don’t fully agree with.

In testing parlance, we battle with Congruence Bias, a related form of False Dilemma defined as an “overreliance on directly testing a given hypothesis as well as neglecting indirect testing.”
Andrew Anderson, Head of Optimization at Recovery Brands, wrote about Congruence Bias on our blog a while ago:
 Andrew Anderson:
Andrew Anderson:
“[Congruence bias is when] you create a false choice such as one banner versus another or one headline versus another, and then test to see which is better. In reality, there are hundreds of different ways that you can go but we become blinded by our myopic view of an answer. You create a false choice of what is there versus what you want to see happen.
[If you] get an answer, it just won’t mean much. Just because the new headline you wanted to try is better, it doesn’t mean that it was good choice. It also means that you can’t apply too much meaning in limited comparisons because you are in reality just validating a flawed hypothesis. It is the job of the researcher or tester to compare all valid alternative hypotheses, yet we get stuck on the things we want to see win and as such we get trapped in this bias on an almost hourly basis.”
Iterative testing is the name of the game. Just because you’ve drawn up an A/B test with a single variation, and it failed, doesn’t mean the hypothesis is misplaced. In reality, there are infinite ways to execute the strategy.

For example, you conduct a solid amount of conversion research and come up with a prioritized list of hypotheses. These aren’t silly things like “test button color.” You’ve done your homework and established areas of opportunity, now it’s time to conduct some experiments.
First on your list, due to extensive survey responses, user tests, and heuristic analysis, is beefing up your security signals on your checkout page. Users just don’t seem to feel safe putting in their credit card information.
So you test security logo vs. no security logo. The result? No difference.
The hypothesis may have been wrong, but the real question you should ask yourself is this: how many different ways are there to improve the perception of security on a page? How many different ways could we design a treatment addressing security concerns?
The answer: infinite.
Bottom line: don’t limit the scope of your testing program by creating false dichotomies. While gamification is fun, sites like WTW that pit A vs B against each other without showing the scope of ideas on the table or previous iterations tend emphasize dichotomies in testing.
To defeat congruence bias (and eliminate false dichotomies) Andrew Anderson advises the following: “Always make sure that you avoid only testing what you think will win and also ensure that you are designing tests around what is feasible, not just the most popular opinion about how to solve the current problem.”
6. The Narrative Fallacy
The Narrative Fallacy is essentially when one, after the fact, attempts to ascribe causality to disparate data points in order to weave a cohesive narrative. It is the same as the Fallacy of a Single Cause in its simplistic attempt to answer the sometimes impossible question of “why.”
The Narrative Fallacy, named and popularized by Nassim Taleb, is everywhere. Once you start reading about it, you’ll start to become annoyed at how often you notice it in daily life.
For instance, you can’t read a Malcolm Gladwell book anymore without seeing the simplistic cause/effect narratives, such as this one on the connection between Asians and their superior math abilities:
“Rice farming lays out a cultural pattern that works beautifully when it comes to math…Rice farming is the most labor-intensive form of agriculture known to man. It is also the most cognitively demanding form of agriculture…There is a direct correlation between effort and reward. You get exactly out of your rice paddy what you put into it.”
The logic: Rice farming → superior math skills because (narrative fallacy).
Andrew Anderson wrote an epic article for the CXL blog on how Narrative Fallacy, and other post-hoc evaluations, can wreak havoc on a testing program. He explained an exercise he used to do while consulting testing organizations:
Andrew Anderson:
“One of the first things I had new consultants do was to take any test that they have not seen the results for, and to explain to me why every version in that test was the best option and why it would clearly win.
Every time we started this game the consultant would say it was impossible and complain how hard it would be, but by the time we were on our 4th or 5th test they would start to see how incredibly easy it was to come up with these explanations:
- “This version helps resonate with people because it improve the value proposition and because it removes clutter.”
- “This version helps add more to the buyers path by reinforcing all the key selling points prior to them being forced to take an action.”
- “This versions use of colors helps drive more product awareness and adds to the brand.”
Keep in mind they have not seen the results and had no real reason what works or what doesn’t, these stories were just narratives they were creating for the sake of creating narratives…
…I used this exercise to help people see just how often and how easy it was for people to create a story. In reality the data in no way supported any story because it couldn’t. One of the greatest mistakes that people make is confusing the “why” that they generate in their head with the actual experience that they test.
You can arrive at an experience in any number of ways and story you tell yourself is just the mental model you used to create it. The experience is independent of that model yet people constantly are unable to dissociate them.”
Bottom line: stop trying to assign a why to your data. If you tested a new value proposition and it won, it could be for many reasons, including the one you tell yourself. But if you assume that it’s because “red is associated with urgency and our visitors need to have urgency to purchase,” then that narrative will affect (and limit) the future of your testing program.
Conclusion
The most impactful limitations of a testing program have nothing to do with data – they center on human behavior and the reality of opaque decision making. At the heart of this problem is the reliance on numerous logical fallacies and cognitive biases that most of us are hardly aware of.
This article outlined 6 common ones we see in optimization, but there are more (cherry picking, survivor bias, and the ludic fallacy to name a few).
If you do optimization – and especially if you’re in a management or team lead role – I think studying these and learning to mitigate them can improve the effectiveness of your testing program.
What has your experience been with logical fallacies? Have you seen any of the above in action? How did you deal with them?
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-
Sometimes A/B testing is made to seem like some magical tool that will fix all…
-
Both your visitor and Google prefer your site to be fast. Increasing site speed has…
-
If you’re part of a conversion optimization team, a big part of that job is…


{kind=link}
Hi Alex,
Great post to read. We all do fall into one fallacies at some point or another while AB testing, it’s good to have such great reminder.
Keep up the good work.
Hey Sebastien – thanks for the comment. Glad you got some value out of the article!
-Alex
Terrific article!
Kudos for such well thought and well researched work.
I’m sharing this with my team first thing tomorrow :)
Alex, I’d love to bump into you some evening at a bar and talk my way till the dawn. You seem like a man of substance.
.
Tushar, thanks for the awesome comment! If you’re ever in Austin I’ll take you up on that