
One-tailed tests allow for the possibility of an effect in one direction. Two-tailed tests test for the possibility of an effect in two directions—positive and negative.
Simple as that concept may seem, there’s a lot of controversy around one-tailed vs. two-tailed testing. Articles like this one lambaste the shortcomings of one-tailed testing, saying that “unsophisticated users love them.”
On the flip side, some articles and discussions take a more balanced approach and say there’s a time and a place for both.
Let’s set the record straight.
Table of contents
What are one-tailed tests and two-tailed tests?
One tailed tests allow for the possibility of an effect in one direction. Two tailed tests test for the possibility of an effect in two directions—positive and negative.
What are the differences between one-tailed and two-tailed tests?
The main difference between these two types of tests is that two-tailed tests can show evidence that the control and variation are different, whereas one-tailed tests can show evidence if variation is better than the control.
Many people don’t even realize that there are two ways to determine whether an experiment’s results are statistically valid. That’s led to a lot of confusion and misunderstanding about testing with one tail or two tails.
The commotion comes from a justifiable worry: Are my lifts imaginary? As mentioned in this article, sometimes A/A tests will come up with some quirky results, thus making you question the efficacy of your tools and your A/B testing plan.
So when we’re talking about one-tailed vs. two-tailed tests, we’re really talking about whether we can trust the results of our A/B tests and take action based on them.
If you’re just learning about testing, Khan Academy offers a clear illustration of the difference between one-tailed and two-tailed tests:
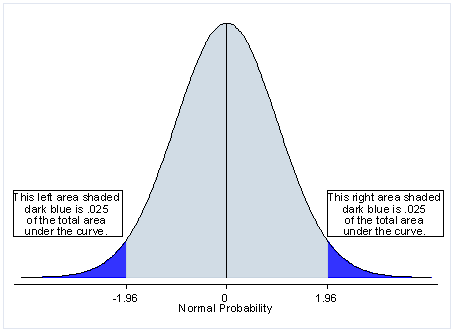
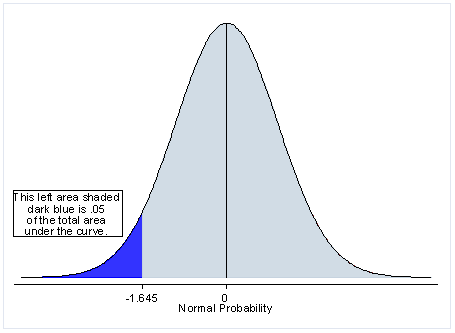
Why would you choose one over another? As mentioned above, the two-tailed test shows evidence that the control and variation are different, but the one-tailed test shows evidence if variation is better than the control.
Chris Stucchio does a great job explaining the difference between the two tests in context:
In frequentist tests, you have a null hypothesis. The null hypothesis is what you believe to be true absent evidence to the contrary.
Now suppose you’ve run a test and received a p-value. The p-value represents the probability of seeing a result at least that “extreme” in the event the null hypothesis were true. The lower the p-value, the less plausible it is that the null hypothesis is true.
Now suppose you are A/B testing a control and a variation, and you want to measure the difference in conversion rate between both variants. The two-tailed test takes as a null hypothesis the belief that both variations have equal conversion rates.
The one-tailed test takes as a null hypothesis the belief that the variation is not better than the control, but could be worse.
Chris Stucchio
Does it matter which method you use?
Okay, so now that we went over what the tests actually are, we can ask the important question: Does it even matter which you use? Turns out, that’s a complicated question.
According to Kyle Rush, it does:
“The benefit to using a one-tailed test is that it requires fewer subjects to reach significance. A two-tailed test splits your significance level and applies it in both directions.
Thus, each direction is only half as strong as a one-tailed test, which puts all the significance in one direction. And, thus, it requires more subjects to reach significance.
Kyle Rush
However, some would say this isn’t an issue to get worked up over:
For some reason, folks are making a big deal about one-tail vs. two-tail tests. Of all of the issues facing you when embarking on testing, this isn’t really the one you should worry about.
If your testing software only does one type or the other, don’t sweat it. It is super simple to convert one type to the other (but you need to do this before you run the test) since all of the math is exactly the same in both tests. All that’s different is the significance threshold level.
If your software uses a one-tail test, just divide the p-value associated with the confidence level you are looking to run the test by two.
So if you want your two-tail test to be at the 95% confidence level, then you would actually input a confidence level of 97.5%, or if at a 99% level, you need to input 99.5%. You can then just read the test as if it were two-tailed.
Matt Gershoff of Conductrics
Pros and cons of each method
Maxymiser (now part of Oracle) laid out some pros and cons of using either test:
| Pros | Cons | |
|---|---|---|
| One tail hypothesis |
|
|
| Two tail hypothesis |
|
|
Other factors in validity
According to Andrew Anderson from Malwarebytes, though, there are many other factors at play when testing:
You also have the issue of a T-Test versus a Z-Test or other Gaussian frequentist approaches versus a Bayesian approach. It is really not as simple as ‘one-tailed vs. two-tailed.’
Andrew Anderson from Malwarebytes
All of this also assumes that you’re testing in an environment where confidence is even slightly useful and validating the underlying assumptions behind the model. For example, in my last two positions, variance has been so high that I don’t even look at confidence as it in no way reflects real-world situations.
So there are other factors when it comes to testing for statistical validity. Still, there are strong opinions around one-tailed and two-tailed testing.
The case for two-tailed testing
A two tailed hypothesis can mitigate Type I errors (false positives) and cognitive bias errors. Furthermore, as Kyle Rush said, “unless you have a superb understanding of statistics, you should use a two-tailed test.”
Here’s what Andrew Anderson had to say:
If given the option, you are much better off using two-tailed versus one-tailed as, fundamentally, one-tailed tests enable more Type I errors and also cognitive bias errors.
One-tail is tempting because it leads to faster ‘conclusions,’ but that just magnifies all the problems with using confidence and does nothing to add value to your organization.
Both are based on similar model assumptions, things like no variance (only population error rate), unbiased sampling, and Gaussian distribution, so they are both very rarely reflective of real-world situations. But the higher bar of difficulty to reach “significance” in a two-tailed test, as well as the measure of both directions, better reflects real-world outcomes.
Most of the time, what we think will be positive is actually negative (see 10% industry average success rate), as well as mitigates (barely) the risk of acting too quickly.
Andrew Anderson
Neal Cole, conversion specialist at a leading online gaming company, agrees:
Personally, I think one-tail tests are not appropriate for most A/B testing and increase the risk of a false positive. When we are A/B testing, we can’t be sure of the direction of the difference in the key metrics.
Neal Cole
Around 50% of tests don’t deliver an uplift in conversion, and so we’re kidding ourselves if we use a one-tail test as our default approach.
When can I use a one-tailed test?
According to some, there is a time and a place for using a one tailed hypothesis in your test. It is often contextual and depends on how you intend to act on the data. As Luke Stokebrand said:
One-tailed tests are not always bad; it’s just important to understand their downside. In fact, there are many times when it makes sense to use a one-tailed test to validate your data.
Luke Stokebrand
Andy Hunt from UpliftROI acknowledges the faults of one-tailed tests but takes a realistic approach:
Two-sided tests are better but not the norm for most marketers or VWO/Optimizely.
Instead of focusing on whether to use two- or one-sided tests, you’d be better off simply letting the tests run for more time to be sure the results are valid and run A/A tests to make sure the control and variation are performing exactly the same.
Andy Hunt
Similarly, Jeff Sauro from MeasuringU reiterates that while you should normally use the two-sided p-value, “You should only use the one-sided p-value when you have a very strong reason to suspect that one version is really superior to the other.”
Kyle Rush echoes this:
If you’re testing a new variation on your website and only want to know if the variation is better, then you would use a one-tailed test in that direction. If you don’t plan on deploying the variation if it doesn’t win, then this is a completely fine approach.
However, this turns into a bad approach if you deploy the variation when it wasn’t a statistically significant winner because the one-directional test didn’t measure the hypothesis in the other direction, so you don’t know if the variation is worse. A two-tailed test applies the hypothesis test in both directions to mitigate this issue.
Kyle Rush
Which tools use which method?
When you ask the question of which A/B testing software uses which method, you enter a world of murky answers and ambiguity. That’s to say, not many of them list it specifically.
So here’s what I got from research and from asking testing experts (correct me if I’m wrong or need to add something):
Tools that use one- or two-tailed tests
Tools that use two-tailed tests
Of course, certain tools have custom frameworks as well. Kyle Rush explains Optimizely’s Stats Engine:
In terms of tools on the market, Optimizely’s Stats Engine makes stats and questions like this very easy for you, much more than any other platform out there. A huge benefit to Stats Engine is that with traditional one- and two-tailed t-tests, you have to calculate a sample size based on an arbitrary variable called minimum detectable effect (MDE).
With Stats Engine, you don’t have to calculate a sample size, (i.e. picking an arbitrary MDE). This has a huge impact because you will often underestimate your MDE when calculating sample size because you’re just picking the number out of thin air, which has the effect of requiring a sample size that can be exponentially larger than what you actually needed to reach significance.
I strongly believe that worrying about questions like this is a thing of the past with Optimizely’s Stats Engine.
Kyle Rush
Conclusion
The issue of using one-tailed vs two-tailed testing is important, though the decision can’t be made with statistics alone. As Chris Stucchio said, “It needs to be decided from within the context of a decision procedure.”
He continues:
When running an A/B test, the goal is almost always to increase conversions rather than simply answer idle curiosity. To decide whether one-tailed or two-tailed is right for you, you need to understand your entire decision procedure rather than simply the statistics.
If you’d like to learn more about one-tailed and two-tailed testing, there are many resources. Here are a few that are easy to understand:
Otherwise, I’ll close with something Peep said about the subject:
The one- vs. two-tailed issue is minor (it’s perfectly fine to use a one tailed test in a lot of cases) compared to test sample sizes and test duration. Ending tests too soon is by far #1 testing sin.
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

When should you use bandit tests, and when is A/B/n testing best? Though there are…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-
When should you use multivariate testing, and when is A/B/n testing best? The answer is…
-
There's a philosophical statistics debate in the A/B testing world: Bayesian vs. Frequentist. This is not…




Do you know how Unbounce calculates statistics?
I don’t, but I’ll ask them to chime in
Aloha,
Just chatted with the developers here. Unbounce uses a Chi-Squared Test algorithm. This is essentially a one-tailed test, however it does detect whether the values are different and not just if A is better than B. This is where it gets complicated :) For more on this check out this thread on CrossValidated:
http://stats.stackexchange.com/questions/22347/is-chi-squared-always-a-one-sided-test
But to Matt’s point, there are many other more and much important aspects to worry about. Also I agree 100% with Peep that ending tests prematurely is the mother of all testing mistakes. You need to run your tests long enough that they provide you with a representative image of how that treatment would impact your business if implemented for real on your website.
– Michael