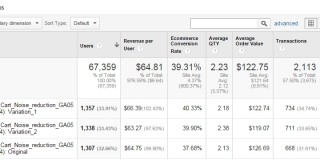
You run an A/B test, and it’s a winner. Or maybe it’s flat (no difference in performance between variations). Does it mean that the treatments that you tested didn’t resonate with anyone? Probably not.
If you target all visitors with the A/B test, it merely reports overall results – and ignores what happens in a portion of your traffic, in segments.
Table of contents
Why is conducting post-test segmentation important?
Your users are different. What resonates with one person, doesn’t work with another one.
If you segment your A/B test results by browser version, you might discover that customers coming from the Safari web browser are converting much better than the average.
You might also notice that people using the Firefox browser hardly convert at all when they see variation B: this could mean that there are some technical issues with the front-end code that make the treatments not work on Firefox.
Noticing which segments respond well (or not all) to particular treatments can make the difference of making money or not.
This is especially true of big businesses:

Chad Sanderson, Subway
“For larger businesses, segmentation is absolutely vital.
The more well-known your company becomes, the harder it gets to directly impact primary KPI’s at the aggregate level because the majority of customers who buy are going to do so irrespective of if your button color is red or blue.
In any experiment, some metric within some group usually changes, but whether we’ve invested in the statistical rigor to discover it is another question altogether.”
Knowing these finer details can help meaningfully shift your metrics in a positive direction, where they may have once been plateauing.
Analyzing data in your post-test analysis
A/B/n test results report results over all of the visitors that were targeted by the test. If the target audience was large enough, they give you an idea of the general trends, but not specific trends within certain groups.
Aggregate data can show no significant difference over time in site data on average; however, when you break that data down into groups, there often is a significant difference in a particular user segment – proving once again all data in aggregate is crap.
Jakub Linowski elaborates on the distinction between certain groups that segmentation in post-test analysis can pinpoint.

Jakub Linowski, GoodUI.org
“One common segment we set-up before starting a test might include: desktop
vs. mobile traffic.
Because the experience and layout is so drastic between these two, even if we detect a positive result in one segment, we might choose to implement only that specific one.
A second segment we typically setup might include: existing customers vs. first-time customers. If both of these segments move through the same screens or funnel, it’s worthwhile to track them separately.
What works for first-time customers might have less of an effect on (and be diluted by) people who are returning to buy again. Similarly, if we detect a positive signal on new customers, but not on existing ones, we would still recommend implementing such a result.”
Tim Stewart offers an Internet Explorer browser example to illustrate how data segmentation after your test can tell you about your site’s functionality:

Tim Stewart, TRS Digital
“I often see a difference in that [low] Internet Explorer [performance is] explained away as ‘these tend to be less technically aware users, and this is a technical product; therefore, we might expect lower performance.’ So, we’ll ignore it.
But a simpler and possibly more likely explanation that might be that the test variant worked less well because the compatibility of older browsers is worse, and quite often skipped, in QA to reduce costs.
The variant was compromised vs control; it was not a fair test of the change in the variant. It was a test on variant functionality, on a smaller sample, from a browser that is likely to have more issues with compatibility.
Yes, in that case, it’s quite probable it has more deviation, more outliers and reports a more extreme difference to the control. Enough to be significant.
I’ve also seen the inverse – the variant was thoroughly QA’d for that browser, but there was an unreported bug on the control. This meant the variant had the unfair advantage; you weren’t testing the hypothesis, you were inadvertently testing fixed vs broken. Pro tip: fixed beats broken.
So that is useful to know, and a reason why you look at segments in post-analysis.
But it’s not to find a ‘winner’ – it’s to ensure data diligence on the overall result by investigating potential issues and increase understanding of factors to consider in subsequent testing.”
Conducting QA on your A/B tests is a must, but bugs can still slip in. Post-test segmentation can help you discover whether any of the treatments are still buggy.
The methodology
Chad Sanderson explains that you must have a methodology to segmentation:
Chad Sanderson, Subway
“Like anything else in CRO, constructing a segmentation methodology is a process, not something to be done on a whim once a test finishes.
Start by asking questions like:
- ‘What segments have true value to our business?’
- ‘What segments are actionable?’
- ‘Which are most likely to be impacted by the test we are running?’
- ‘What type of correction must I do to account for multiple observations of the treatment?’”
Once you’ve asked yourself these questions and developed some answers, you can scour your data and divide along your chosen lines.
Avinash Kaushik offers an excellent guide on how to segment your users between source, behavior, and outcome.
A word of caution when segmenting, though: the more segments that are compared together, the higher the probability of error, so choose wisely and make sure your data is relevant. No need to compare apples to oranges.
Segmenting your data: before or after your test?
Many optimizers don’t like segmenting in post-test analysis, preferring segmented tests from the get-go.
Chad Sanderson explains why he prefers segmenting beforehand, which he calls “pre-registration.”
Chad Sanderson, Subway
“The idea behind pre-registration is simple: By choosing the segments you believe will most likely be affected by the test in advance and (here’s the important part) sticking to those analytical rules, you’ve significantly reduced the probability of randomly stumbling upon false positives by accident.
To understand why, imagine we are conducting a 3-point shooting contest with recreation league basketball players. The participants include some really bad players, some average players, and some good players.
Based on the shooting contest, we want to figure out which segments of people have more good players than bad players.
After taking lots of measurements in advance, we’ve discovered that players who are mediocre typically score 2 out of 10 times, on average. This means that an average player should only get lucky and make 4 out of 10 shots 8% of the time.
After the contest is over, we see there are some surprising groups that made 4 out of 10 shots or more on average: 18-20-year-olds who like The Daily Show, gas station clerks, people who idolize Gordon Ramsay, high school basketball players, and vegan poker experts.
If you had to guess, which group is most likely to be truly better at basketball, and which are more likely to be the result of random chance?
We can observe this same phenomenon in segmentation. The more segments we observe through exploratory analysis, the higher probability we will eventually find some cluster of users that achieve statistical significance.
By choosing audiences in advance, we can dramatically limit the amount of type I errors we might see in our data.”
Segmenting tests from the beginning doesn’t always help you with your discovery process. The goal of a test is to figure out which segments respond to which treatments, and often that’s hard to do if you divide them before you even start testing.
Tim Stewart prefers segmenting beforehand but says that errors can occur both before and after the test.
Tim Stewart, TRS Digital
“Slicing up the data into ‘n’ samples increases the risk of type errors. In addition to lower statistical confidence and higher volatility of smaller samples, if you slice enough samples, you are highly probable to find a result that reports a significance but is a false positive.
It looks different, it reports as significantly different at the confidence you selected for the full test, but it isn’t.
It’s very easy and indeed tempting to the pattern-spotting human-ape to find an odd result and then retrospectively hypothesize a reason why that might be the case. Inventing an explanation to fit the data, not testing against the original hypothesis.
So, if you are doing post-test segment analysis you need to double – and triple – check that you aren’t cherry-picking just to find a result.
Do so with the understanding of the statistical complications and the cognitive bias you are introducing. Keep in mind that this is being used to understand the component factors of the overall result, and perhaps inform further exploration and hypotheses to test.
Make sure you are not selectively adapting your sample just to find a result you can declare as definitive on an otherwise unclear or unexpected result.”
How to test to ensure valid results
As Tim said, whenever you decide to test, making sure you’re efficiently following testing process guidelines to ensure valid results is crucial. Setting up a test is not the time to go rogue and throw the rule book out the window.
Claire Keser of WiderFunnel offers some tips for testing:

Claire Keser, WiderFunnel
“ […]Results aren’t always trustworthy. Too often, the numbers you see in case studies are lacking valid statistical inferences: either they rely too heavily on an A/B testing tool’s unreliable stats engine and/or they haven’t addressed the common pitfalls […]
Use case studies as a source of inspiration, but make sure that you are executing your tests properly by doing the following:
- If your A/B testing tool doesn’t adjust for the multiple comparison problem, make sure to correct your significance level for tests with more than 1 variation.
- Don’t change your experiment settings mid-experiment.
- Don’t use statistical significance as an indicator of when to stop a test, and make sure to calculate the sample size you need to reach before calling a test complete.
- Finally, keep segmenting your data post-test. But make sure you are not falling into the multiple comparison trap and are comparing segments that are significant and have a big enough sample size.”
The elephant in the room: sample size

In general, a good guideline is to stop an A/B test when three conditions have been met:
- Large enough sample size (based on pre-test sample size calculations)
- Long enough test duration (minimum 2 business cycles, so 2-4 weeks)
- Statistical significance 95% or better
When data is segmented, however, this can divide up your sample size into chunks that simply aren’t large enough.
If the sample’s too small, it doesn’t give you the full picture – you’re only seeing a small percentage of your visitors and your data can’t be counted on for statistical validity. (You want uniform sampling to avoid The Simpson’s Paradox.)
Tim Stewart agrees that you need to make sure the sample size of your smallest segment is large enough to detect the expected difference.
Your experimental controls, Stewart says, need to be equal: sample size, performance range, and distribution of outlier behavior. Control inequalities can introduce different weighted averages within a segment, between segments, and against the whole, which gives you inaccurate data.
Tim Stewart, TRS Digital
“I do look at segments within a test both in planning and post-test analysis. The overall average is made up of the performance of its component parts. Understanding what contributed to that total can be an important learning from a test […]
Think of a Formula 1 race. The race is planned for 70 laps, fastest time to complete all these laps wins. But if you only pick two cars to investigate and 10 laps where the difference between them was big enough to be visible and consistent for most of those 10 laps – is the one you picked the winner?
If you then drill down and look only at one corner, averaged over those 10 laps. Is the fastest car through that one corner the winner? Possibly. Possibly not.
You can answer which is faster for that corner for the snapshot you took. But that’s a different question. You can’t compare against the rest of the race and other corners without a great deal more context.”
Smaller changes aren’t reflected in the overall data as the number is usually too small to affect lift. Without segmentation, insights like these would be missed – segmentation gives context.
Follow up tests
In order to account for the decreased sample size, you should run your original A/B test for double the amount of time you normally would, especially if you know in advance that you’ll be segmenting your results.
Jakub Linowski explains that when you decide to segment indicates if you should conduct re-testing:
Jakub Linowski, GoodUI.org
“One key criterion for deciding whether or not to take action on segments is whether the segment was defined before or after an experiment.
If the test was designed with a segment in mind, the setup usually has enough statistical power to allow a decision. If on the other hand, some signal is detected by slicing and dicing random segments, it becomes important to ensure that enough power exists (by extending the test duration or re-testing).”
If you don’t know beforehand that you’ll be breaking up your results into segments, launch follow-up tests for specific, well-performing segments until you get a proper sample size to figure.
This will let you know if there’s something there or not. Without doing this, you’re relying on misleading, invalid data.”
How big should your sample sizes be for follow-up tests?
You need to calculate the sample size in advance for that particular segment. You can set the expected uplift to what you were seeing in your original test.

For example: if in the original test you saw a big uplift inside that segment (ex. +30%), you don’t need as many people to be part of the test to achieve statistical validity.
The caveat, though, is that if the lift is small (ex. 5%), you need a much larger sample size.
Looking past biases and focusing on data
Making a priori assumptions about reasons data has manifested a certain way can get you into trouble.
Tim Stewart discusses some testing problems he’s encountered in his career:
“Also common is a device split, sometimes with potentially valuable insight being dismissed because of prior accepted ‘knowledge.’
People report, ‘We know conversion to sale is lower on mobile; consumers research on mobile, the buy on their desktop. [We see this pattern all the time] outside of a test.’
Then, seeing desktop variant outperform the control, the mobile version shows no difference, or clear small negative, but a net gain on the overall. So, it’s declared a winner.

But more useful would be to ask and test why mobile is ‘accepted’ to perform worse. Why is it easier to detect 10% vs 12% desktop than 5% vs 6% mobile?
Ask: Why is the baseline lower? Why was the effect less/more pronounced – because of actual change, or because lower baseline means more sensitivity to volatility?
Was the variant designed mobile-first? Or was the concept for desktop crammed into less real estate and genuinely works less well.
Or is the main lever in the test, the hypothesis you are exploring, simply clearer on a larger screen, barely visible on a mobile screen?
Are the mobile users differently motivated? More time pressure, different part of the buying cycle, different day of week time of week pattern?
Is the mobile sample large and different enough to report as ‘significant,’ but not representative enough of a different buying, research, or user motivation cycle?
I’ve worked with several clients who had a clear pattern in logged-in user tests, where we can track and consistently test the same user experience across devices.
Patterns like: a customer researching on a desktop during the week, then purchasing via mobile when at the desired location on the weekend. Or even web surfing from the sofa during the evenings, followed by a desktop purchase at lunchtime the following day.

There was also the pattern of a consumer purchasing on desktop during the week, then checking the site on mobile for a different purpose when at their desired location (flights/ticketed events).
There are lots of scenarios where the user would be counted in test but has either bought on a different device or has a different motivation for their mobile visit (check delays, confirm details, access boarding pass, etc.) which means they won’t buy.
That creates a big imbalance in signal to noise on one device or another, which needs to be considered. Ideally in planning, but also in post-test segmentation.
The motivation for visit, user’s desired outcome, and unrepresentative samples can also be a big factor in marketing channel segments.
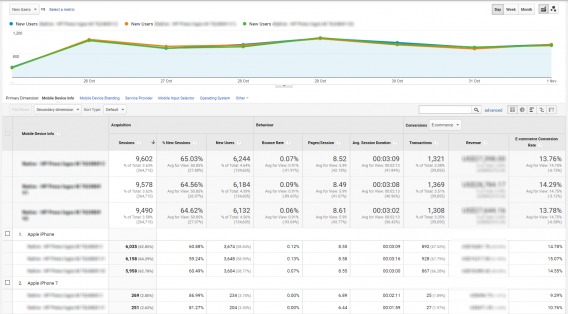
An example of on of our segmented tests, for illustrative purposes.
Is the variant doing a better job of making a key offer prominent and then shown to a Paid search audience that has a high proportion of users visiting for that offer?
Segmenting helps uncover these sort of patterns, errors and omissions, but this is something to establish prior to test and plan accordingly.
Post-test analysis and interpret segments with this in mind. But it is statistically questionable to declare these as definitive if the hypothesis and sample weren’t consciously built for this detail.
In those scenarios, where you can ensure the user is allocated to the same experience, you can sometimes run a hybrid test – a different treatment for the same concept between devices/screen sizes/offers/expected user motivation.
But the main hypothesis then becomes: ‘Did we get the balance right?’
You’re second-guessing different motivations/segments and developing different solutions for context. So, the test and analysis is reporting if that hybrid approach had merit.
Segmentation lets you look at things like whether a win on mobile cancels out a loss on a desktop (or vice versa), or whether a campaign or email meant the sample was unfairly biased in the test period.
Post-test segmentation can help identify these areas, which feeds into pre-test planning and potentially testing specific areas with appropriate context and sample planning.
You can then plan and run completely different tests with device-specific hypotheses, concepts, sample sizes to account for the different levels of noise, effect size and user motivation.

But ultimately whether this is worth it depends on the cost to do this. Calculating the opportunity cost, risk exposure, test cadence vs your ability to implement segment specific outcomes, and the value in doing so.
Because if you can’t implement (or it is prohibitive to do so), then testing a context-specific treatment is useful intelligence, but not revenue-positive.”
What do you do once you find that a particular treatment works better for a segment?
If the segments in question are big enough, the typical answer is personalization: provide different segments a different experience depending on what works best for them.
It’s difficult to manage this by creating manual rules inside your personalization tool. Machines are way better than humans at this. For example, Conductrics’ machine-learning based algorithm can learn these personalization rules by itself (which particular segments respond to which treatment), and adjust traffic between various experiences automatically.
Chad Sanderson details some of the tools and the importance of zeroing in on a specific audience:
Chad Sanderson, Subway
“In order to take advantage of segmented data, you must have some way of displaying winning variations for those users. What’s the point of running a test on ‘visitors who arrive when it’s foggy outside’ if you can’t even serve content to that segment in the first place?
There are several programs that do this effectively: Adobe Target’s profile scripts are top of the class, as are Oracle Maxymiser‘s and Conductrics rules-based targeting capabilities, but there are certain tag management systems and of course custom solutions that accomplish this just as well.
However, it’s important to remember that just because a particular segment can be analyzed doesn’t necessarily mean it can be targeted. For example, Adobe Analytics (Omniture) only allows the use of historical data for personalization.
This means reporting information isn’t available for serving at the visitor level until 48 hours after that user hits the web property.
That cuts out any “first visit”-based segment like ‘new visitors.’ (Although, as mentioned, Adobe does have many other ways of accomplishing this).
In the same vein, consider a metric like ‘time on site.’
Sure, maybe visitors who spend more than 4 minutes on-site are more likely to convert when exposed to a particular test treatment, but if they are spending that time after viewing the test content, how will you target them?
Segmentation is highly contextual, and the rules vary widely depending on the type of segment that is being analyzed.”
Conclusion
User segmentation can be vital to gaining insights and maximizing revenue. When segmenting, keep in mind that you need large enough, valid sample sizes for each of the segments you’re analyzing.
Whether you should go for pre-registration or post-test analysis approach should be determined by your business needs and issues specific to your web property.
Related Posts
-

A/B testing tools like Optimizely or VWO make testing easy, and that's about it. They're…
-
Here’s an uncomfortable truth about conversion rate optimization: lots of people are running bad tests…
-
A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there's…
-
The correct answer is of course that you should start testing where you have the…