
When it comes to traffic acquisition, the money is in the headline.
But testing content headlines comes with a unique set of problems.
Table of contents
The Challenges With A/B Testing Content Headlines
There can be great value in testing content titles. Clearly.
Look at Upworthy, BuzzFeed, or Huffington Post. They’ve made fortunes on publishing must-click headlines (good for them, bad for humanity I say). And of course they test them.
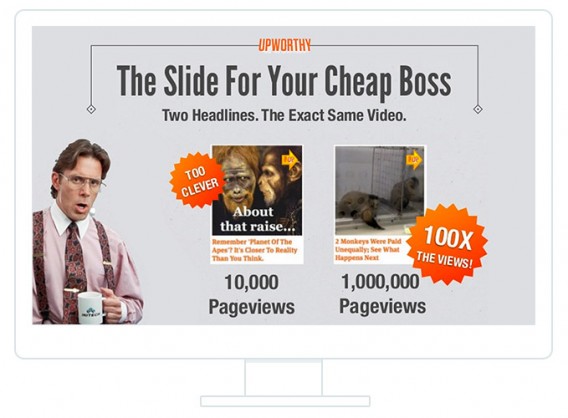
When you test an element of a landing page – say you’re testing a few different hero images – you can, through a brief period of ‘exploration’ (A/B testing), exploit the winning variation afterwards to great reward (greater future revenue).
A headline, however, usually has a limited lifespan in terms of its value. That’s to say an article today won’t have as much value tomorrow and will have even less the next day – especially on a media site that puts out a lot of timely content.
So an A/B test that takes 4 weeks to reach significance and validity doesn’t really let you ‘exploit’ your winning variation.
And even if you’re telling yourself that you’re ‘learning’ which types of headlines generally work better, well that too is a narrative fallacy – you can never really pinpoint the causality when testing headlines.
In addition, there are many confounding variable inherent in content headline tests (which is why they’re so tricky compared to other on-site elements), like:
- The content of the article.
- Any images you use.
- Time of day, week, year.
Sometimes, too, a headline test can win on engagement (more people click through to the article), but people spend less time on page (for media sites this is usually a bad sign) or they don’t complete desired actions (like clicking on CTAs on the site).
There are many blog posts out there that talk about A/B testing content titles, but what they’re performing aren’t really A/B tests – at least not proper/valid ones. Here are a few of the approaches I’ve seen and some reasons they may not be as illuminating as you think.
Social Media as a Testing Proxy
The most common solution to testing content titles I’ve seen is to test different variation via social media, usually on Twitter. This approach was made popular by Buffer, who summed up their process like this:
“Our specific headline process looks like this:
-For each post, we brainstorm five to 10 headlines and decide among the marketing team which ones we like best.
-The winners from step one become our test candidates. We take three headline variations and post them as updates to our Buffer Twitter account. Ideally, the closer together we can post them (e.g., all in the morning or all in the afternoon), the more reliable data we can expect to receive.
-We track the results in Buffer analytics to see which headline performed best. The winner becomes the new headline on the post (or stays the same, depending on what we started with).”
It’s not hard to spot the problems in this.
First – and this isn’t easy to solve – the audiences aren’t randomized. I could see, and click, both variations.
Second, if they’re sending the tweets at different times – say the first at 9am and the second at 11am – the results are skewed because of the time variable. Maybe more people are reading your tweets at 11am. Maybe they’re more engaged at that time. No one knows. The point of an A/B test is to control external variables such as time, and doing this leaves that variable on the table.
Third, they aren’t looking for a single metric and are instead eyeballing which one is better based on multiple metrics. Retweets, favorites, mentions, etc.
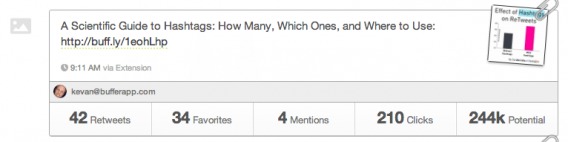
This was their first version:
And the second (what they declared as the winner):
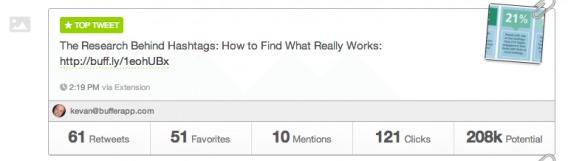
Because there were more mentions and retweets, they ruled the second one the winner. Clicks and potential, however, were higher on the ‘losing’ variation. I’m not saying they made the wrong decision with the winner, but I’m saying if you don’t have a clear definition of a ‘winning’ test, you’re opening yourself to confirmation bias, where you look for evidence that confirms your existing beliefs. You’ll surely be able to argue a point for your favorite variation.
In addition, it might be the same people retweeting and favoriting both (especially with all those auto-retweeting bots on Twitter).
In fairness, they do acknowledge some of these shortcomings:
“Of course, it might also be best to point out that A/B tests on social media are not perfect. The varying times of day that we use in our testing can make for significant variables, as can the images we use to share along with the headlines. In the end, we’re just interested in gaining any edge we can to make a headline more meaningful for our audience, and this Twitter test has been a useful indicator so far.”
Using Facebook Ads to Test Titles
As a way to control some of these variables, Pizza SEO uses Facebook ads to test content audiences on a more controlled sample.
What they do, essentially, is set up Facebook custom audiences based on interest. While you can’t split age evenly, they ensure very little overlap by splitting their test groups like this:

So 21-22 is in group A, 23-24 in group B, etc.
Then they make two ads with only the headline different (of course, they could also test other elements this way like the photo as well):
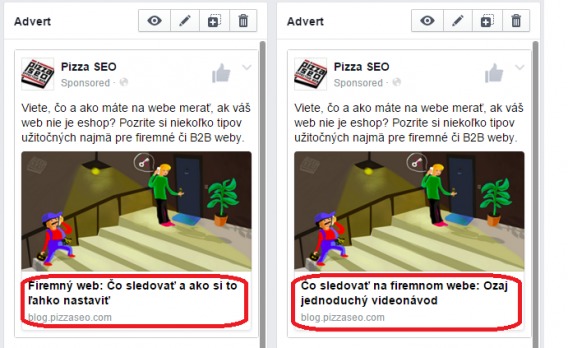
This way, they were able to calculate an adequate sample size and let the test run to significance based on CTR. More than that, they also set up UTM parameters to track each variation’s on-site behavior:
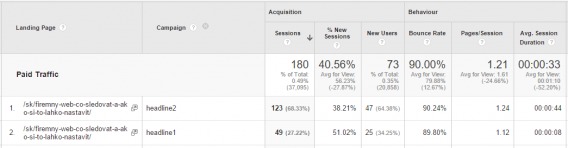
This version of testing on social media is superior to the Twitter version above, but still suffers from a few drawbacks.
One, there’s the cost of advertising (which probably isn’t all too much, but still, it adds up). Then two, and more importantly, is the time cost of implementing a test for each article. If you publish a lot, you could be spending quite a bit of time testing insignificant changes while you could be doing more important things.
Testing Content Titles via Email
Campaign Monitor says they A/B test their headlines using email:
“Campaign Monitor will send one version of the email to one part of the list (we choose to send each version to 10 percent of our list), and the other version to another part. It’ll then measure the results and automatically send the best performing email to the rest of the list.
Aside from adding in the additional subject line, there is literally no extra work in sending a subject line test in comparison to sending a normal email campaign.”
If you have a big enough list, you can send the test out to a small portion of your list (say 10%). Then, once you’ve deemed a ‘winner,’ revise the title on your site and send with that title to the rest of the list, too.
This is idea of only testing on a portion of your traffic can be extended to the actual article itself (if you have enough traffic).
Testing on a Small Portion of Traffic
Similar to what you can do with email subject lines. Send to 10% of your list and then decide based on that data which version to send to the rest. Apparently the Huffington Post does this (or at least used to according to this 2009 Nieman Lab article):
“So here’s something devilishly brilliant: The Huffington Post applies A/B testing to some of its headlines. Readers are randomly shown one of two headlines for the same story. After five minutes, which is enough time for such a high-traffic site, the version with the most clicks becomes the wood that everyone sees.”
If you’ve got the traffic, this is a solid approach. Technically, it’s a version of bandit algorithms known as an ‘epsilon-first‘ approach. HuffPo is basically uniformly collecting results – as you would in a regular A/B test – but not using a hypothesis test to make a selection. They just shift all traffic to the winner after a certain point.
Multi-Armed Bandit Testing
Image you’re in a casino.
There are many different slot machines (known as ‘one-armed bandits’, as they’re known for robbing you), each with a lever (and arm, if you will). You think that some slot machines payout more frequently than others do, so you’d like to maximize this. You only have a limited amount of resources – if you pull one arm, then you’re not pulling another arm. Of course, the goal is to walk out of the casino with the most money. Question is, how do you learn which slot machine is the best and get the most money in the shortest amount of time?
That, in essence, is the multi-armed-bandit problem. And they’re great for short term testing, which includes promotions and, of course, content headlines.
Chris Stucchio, data scientist at VWO, wrote about bayesian bandit algorithms a while ago, using a historical editorial example to show how they work:

Chris Stucchio:
“Great news! A murder victim has been found. No slow news day today! The story is already written, now a title needs to be selected. The clever reporter who wrote the story has come up with two potential titles – “Murder victim found in adult entertainment venue” and “Headless Body found in Topless Bar”. (The latter title is one I’ve shamelessly stolen from the NY Daily News.) Once upon a time, deciding which title to run was a matter for a news editor to decide. Those days are now over – the geeks now rule the earth. Title selection is now primarily an algorithmic problem, not an editorial one.
One common approach is to display both potential versions of the title on the homepage or news feed, and measure the Click Through Rate (CTR) of each version of the title. At some point, when the measured CTR for one title exceeds that of the other title, you’ll switch to the one with the highest for all users. Algorithms for solving this problem are called bandit algorithms.”
Bandits are a great way to balance earning with learning. Essentially, they attempt to minimize regret by exploiting learnings in real time, and shifting favor to higher performing variations gradually.
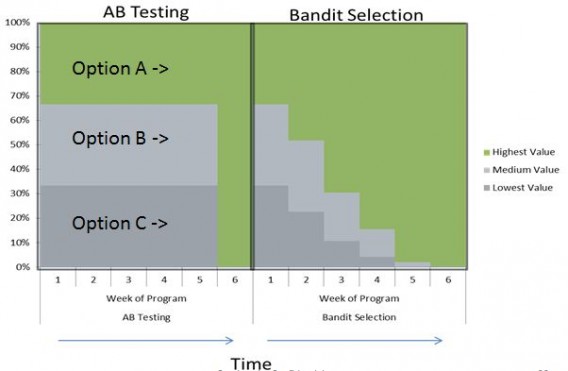
Here’s Matt Gershoff, CEO of Conductrics, explaining why bandits may be the best option for headline testing:

Matt Gershoff:
“If you think about it, assuming you really just want to optimize, there are three main reasons to prefer a bandit approach for experimentation:
- Perishability – if the value of any information you gleaned from the experiment degrades fairly quickly;
- Scale – if you need to run 10’s or even 100’s of a certain type of experiment, it might be more efficient to just let the application self-tune;
- Complexity/Targeting – often you want to learn and assign the best experience for each customer, rather than just picking one experience for every customer. A bandit approach can learn and apply the more obvious customer assignments (rules) first while it is still experimenting to find other less obvious targeting rules.
The reason Headline Testing makes sense to treat as a bandit problem because it has at least one of these conditions, and often all three: it is perishable; often is at scale; and in some cases different headlines may appeal to different users.
Second, there really isn’t a true default/control that we have to worry about doing worse than. With many A/B testing approaches, there is an implicit ‘first, do no harm’, built into the testing logic. In this case, there is no existing headline, so we are more free to pick whichever headline appears to be performing best.”
The Washington Post uses multi-armed bandits to optimize their site’s content – headlines, photo thumbnails, video thumbnails, recommended articles, and much more. They explain the benefits of using bandits for headlines as opposed to A/B tests:
“The bandit first explores all the arms of a test and monitors user feedback for each arm. The feedback for each arm (the number of times each variant was served and clicked) is used to calculate the degree of user engagement with that arm. This real-time user feedback is used to increase the confidence about the performance of each arm until the bandit converges to just serving the best performing arm.
This is a completely automated test experience since there is no explicit requirement to end the test to stop the worst performing variants from being displayed.
In contrast to another popular testing paradigm called A/B testing, MAB tests are more flexible in nature since new variants can be added and old and underperforming variants can be deleted even while the test is running. This is not possible in a traditional A/B testing paradigm. Also an A/B test needs to be stopped explicitly since worse performing variants of a traditional A/B test are served in the same proportion as the best performing variant..”
And though they won’t say they use them, I’m fairly certain Upworthy employs bandit algorithms as well (their editor calls their tool a ‘magical unicorn box’).
Here are a few tools you can use that employ bandit algorithms:
Conclusion
Content title testing is hard because:
- It’s difficult to perform a truly controlled experiment.
- The window of value for exploitation is small.
- External validity factors are rampant.
Therefore, many of the blog posts you’ve read that claim to have solutions are idyllic. They make claims that don’t actually have scientific grounding.
The way that most of your favorite sites test content titles is through sophisticated bandit algorithms. If you can execute bandit tests, go for it. If not, don’t think that posting two different tweets will give you a strong or scalable answer.
Related Posts
-

A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there's…
-
The correct answer is of course that you should start testing where you have the…
-
While running A/B tests on all your traffic at once is often tempting, it's best to…
-
A/B testing splits traffic 50/50 between a control and a variation. A/B split testing is…




Just another reason if you don’t do PPC and are an “organic” guy to do use PPC. Spend 20 or more hours developing a blog post or other piece of content without testing the headline first via PPC, you are likely undercutting yourself pretty badly.