
One of the great truths that people ignore when it comes to optimization is that you can fail with any tool. It’s only when you are trying to succeed that differences in tools really matter.
Once you’ve established the right mindset for a successful program you are still going to need a number of tools to enable you to test and to get value from your actions. I’ve helped setup hundreds of programs, and there is a huge difference in both how tools get implemented and how people think about their tools as either the entire purpose of the integration or as a means to an end.

Like all things it is not a matter of falling for Maslow’s Hammer but instead about looking at your tools for how they enable you and how they allow you to do things you have not done before.
I will present a few of the key tools that you will need in order to get a program underway. Instead of talking about specific tools it is better to think in terms of what you need and why, as well as what you don’t need and what to avoid. You can have all the best tools and get no value, just as you can have the cheapest tools and get great value. The key is in how you use the tools you have. This will allow you to view any tool and make it fit within your organization and customize it to your needs instead of trying to find a perfect turnkey solution that likely does not exist.
Table of contents
The Biggest Tool – Your Testing Solution
The first thing most people think about is their testing solution. Its hard to have a program if you can’t run a test. That being said it is actually one of the least important parts of the program as there is surprisingly little differentiating most tools.
Vendors try and make it sound like their tool is the greatest thing since sliced bread. The important thing to understand is that despite so many promises and bells and whistles, most of what is talked about has no bearing on achieving success. There is no perfect tool– hey all have some good and some bad. The key is to figure out what fits best for enabling you to do the right things while also helping you avoid the wrong actions. Instead here are some of the key factors to look for and key items to ignore when you choose your tools.
Speed
When thinking about speed there are two different factors that matter. The first is after your initial deployment and set-up, how fast can you get a test from concept to execution to live? The goal for any program is to get most tests with at least 5 experiences through that concept in 30 minutes or less. That is a hard target to meet but it does express just how important it is to prioritize speed in testing and the need for general knowledge of CSS, HTML, and Javascript by the operator.
This means that items such as templatized rules, easy site interaction, easy interface, and easy navigation are vital. It also means that tools that require complex URL targeting rules, constant IT deployment, or require manual jQuery set-up should be lowered on your priority scale.
An example of a tool that for the most part does this right is Optimizely while an example of those that doesn’t is SiteSpect.
The other concept of speed is how much load time does it add to the site, in both weight and in speed execution. The general rule of thumb is that the human eye notices things in the 200-300ms time range, and noticing a change changes people’s actions. This means you need a tool that does not overly weigh down the page and one that does not overly cause post page interaction changes. Tools that rely on heavy jQuery can seem like amazingly easy to use, but they can also cause page flicker or interaction effects. Learn how to reduce the flicker effect here.
Tools that allow for multiple ways to interact with a page and/or allow you to control items as the page loads have major advantages here.
Note: While lots of tools provide easy-to-use visual interfaces to create treatments, the automagically created jQuery code is often terrible – which results in cross-browser compatibility issues and slowness. Always have a developer check and improve the code. Or learn jQuery – it will really help.
Consistency
Another key factor is to avoid any tool that looks at people on a session basis, or enables the ability to drop people from an experience while it is active. While most people are used to thinking about things in terms of sessions, the truth is that it doesn’t matter if something happens today, tomorrow, or 3 sessions from now.
What matters is being able to influence a behavior for the better. It is vital that you use a true visitor based metric system, and test design during the test and that you look at behavior over time. Tools that do not explicitly do this and even tools that allow for this view and behavior but do not do so out of the box can cause havoc.
Adobe Target is a tool that does a great job of leveraging a visitor based metric system while Google Content Experiments is visit based.
Segmentation
While it is possible to use other data sources as your system of record for analysis this behavior is not without its drawbacks. It is vital that you focus not on targeting capabilities, but instead focus on the ability to look at many different views of the same users. Tools that do not have easy to use and robust segmentation abilities or that focus solely on targeting instead of segmentation can limit the value of your program. Even worse, these tools can enforce bad behaviors and enable groups to think they have accomplished something when they have not.
You should be able to create many different custom segments based on a series of factors. Tools that limit the number of active segments for analysis, or that make it difficult or cost prohibitive to use certain types of segments can be problematic.
Even more problematic are ones that encourage the use of segments that are so small that they suffer from a massive barrier for value in a mathematical sense. You have to always do your own thinking (e.g. check the sample size of segments).
No tool does a better job on segmentation then Adobe Target while segmentation is a problem for Optimizely (which is why you might want to use Google Analytics to do post-test segmentation and analysis).
Data
Data is a big part of the picture. Most tools enable you to track many different things, the key is both what they encourage and how easy it is to track what you need to track. Avoid tools that focus on tracking pointless behaviors like engagement, clicks, or time on site. Instead you want tools that allow for consistent and meaningful behavior of your single success metric (e.g. transactions, revenue per visitor).
Tools that focus on pointless things like heat maps, click tracking, or that highlight the ability to track a large number of metrics at the same time are doing a great job of telling you that they are deeply invested in you feeling like you are successful even when you are not getting value from your tests.
VWO is can lead you astray with heatmap data while Google Content Experiments, for all its other limitations, does a good job of focusing on one key metric.
A second dimension of data is how the tool purports to tell you when you can act on a test. To put this simply, ignore all of it as there is not a tool out there that does a good job and that does not overly rely on rough statistical measures to express confidence. There are minor improvements from a single tail to a two tail to Bayesian or Monte Carlo types of evaluations but even in the best case they are functionally not enough to ever tell you when a test is done. The fact that vendors make this as much of a focus as they do helps highlight how far the distance is from what they present as a successful test and what is a viable outcome.
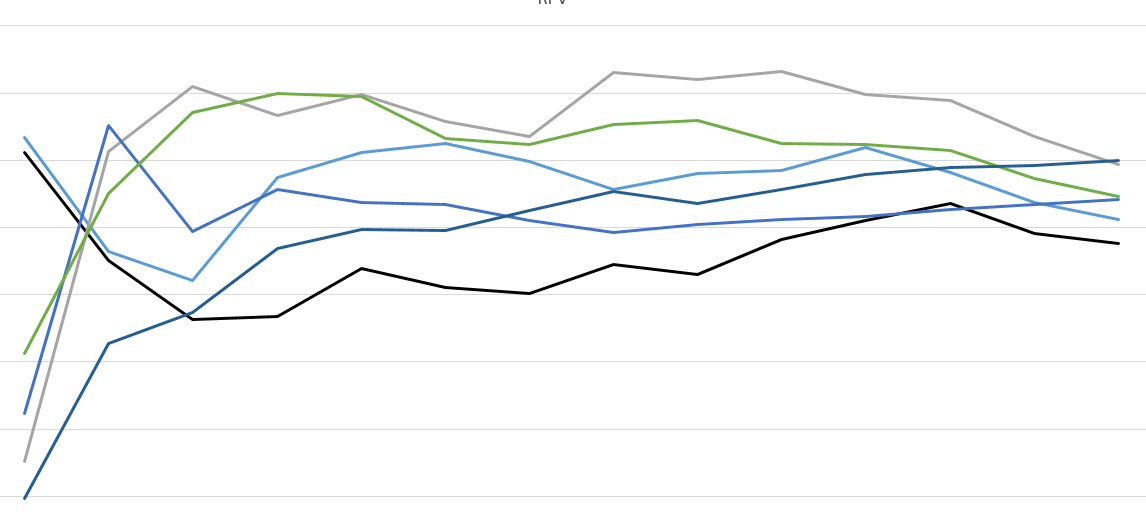
Another dimension that is often overlooked in choosing a tool is the graphical representation of the data. Any tool that makes it hard or does not present the ability to look at a cumalative data graph in a meaningful way makes it nearly impossible to make good decisions.
While I would strongly suggest that you do all tracking in an outside medium such as Excel, you can often tell far more from the graph then you can from just a basic summary screen. Too many people look at their tools for what they say in a summary screen or just as a basic reporting level and spend way too little time thinking about the readability of the graph or the ability to look at as many comparative data segments as possible meaning they miss a huge amount of a value a tool should be providing.
Integrations
Having the ability to easily integrate with other tools or your other reporting systems can be a good thing, but it can also lead to really bad behavior. Remember that the analysis of causal data is very different than normal correlative analytics or even qualitative data. How you think about, how you report, and what the data means is completely different.
While it is possible to enrich it with those, it is even easier to get side tracked or fall back on more comfortable disciplines when you have access to those tools. s such you should think before just moving forward with any integration. Making it easier to have poor discipline is not a value add and is instead a value detractor, so always keep discipline in mind when looking at how you are going to integrate your testing tool with your other existing tools. While a blind squirrel might get a nut every now and then the odds are not in his favor in the long run.
That being said the ability to easily integrate with another tool or two should be as simple as a plugin or a simple switch. If it involves a lot of back end support or an API call it is not the end of the world but it can lead to maintenance cost and speed errors in the future. Having the ability to tie into your CMS can be of high value, but not if it drags down test creation speed to an absolute halt or if you are not able to test layouts and real estate because you are beholden to a template.
Having the ability to pass useful information about users in a runtime environment can help you get a lot more value from segments, as long as the focus is on the discovery of value and not just blind targeting. Anything that is not done on initial pageload is going to dramatically impact the population on which it can be leveraged so keep that in mind when looking at the value of different data imports.
Optimizely is extremely easy for integrations with a number of tools while Adobe Target has the capability, but is very resource intensive to set-up.
Implementation
There is always going to be an upfront implementation cost to set-up any tool, no matter how easy some one-tag solutions purport to be. Going into the set-up of your tool with this in mind and with the goal of setting up things in a way that are universal from day one will save you a lot of headaches down the road. Too often things get deployed on an as-needed basis and this leads to a lot of slowdown and misconceptions about the speed and value of a tool.
A lot of tools have exploited this gap by focusing on how easy they are to set-up and get going. This is true in some cases, but ultimately the first few days or weeks of your tool use should not be a deciding factor in which tool you leverage. Always plan the right time and resources to set-up a tool so that you can meet that 30 min rule in the future and so that needed information is there from day one. Don’t go with a tool just because you can add a single tag at the top of the page for that sole reason. Also do not choose a tool just because your group does not have to do the work. Asking your net ops team, like SiteSpect does, to do the heavy lifting is not a good reason to justify a tool.
Ultimately once you are done with implementation your tool should become ubiquitous. You should rarely have to change your set-up, and you should be able to treat the tool as an after thought. It is just the thing that you leverage, it should not be the end all be all of your program.
Knowledge of how to setup a test or run a tool is required but it is so low on the list of priorities that determine success that once you get past the initial pain it has to be a background hum instead of a constant beat. If it is not then you need to really look at if you have the right tool or if you set up things correctly. A small bit of pain now can save you from massive headaches later.
Natural Variance
No matter what you do if you compare the same experience to copies of itself it won’t match. This is known as variance and it is very important to know what the range is for your tool and site as this is not accounted for in terms of population error rate in confidence and other measures. It will be a big factor in how much you can act on small lifts and what you can test, so it is not something to take lightly. his is the number one most overlooked and misunderstood fact for most tools and programs.
Every tool has a degree of natural variance just because of the nature of data collection. That being said the data system and the way it is set-up on your site can have a major impact to just how much variance exists. If you can run a beta for your tool before you make a full purchase, that is great, but even if you can’t you need to know your variance before you can do just about anything. Tools that focus on a visit based metric system and sites with lower populations or limited product catalogs are going to have higher variance.

Many people mistakenly think running just an A/A variant is enough to get a read on variance, but the truth is that variance has a range and normalization pattern, just like every point of data. This means you need to do a full study, and you need to know how to look at that data. I normally suggest you do 5-6 experiences of the same thing and run under the same conditions of most tests on your site. 6 experiences gives you 30 data points which means that you will have a much deeper view into averages and normalization, as well as the beta at given times in the test cycle. You can do this as little as once a year, though I suggest more often than that.
Natural variance can shape your entire use of other parts of the tool such as confidence, and it can have a major influence on what you test and what you can call a winner. Most sites on sitewide metrics overtime end up around a 2-3% variance range.
I have worked with top 50 websites that have had average variances as low as 1% and worked with smaller lead based sites that had variance as high as 6-7% after two weeks. What is important to note is that whatever that range is you have to treat all results in the plus or minus of that as neutral or impossible to get a read on, even if you get 100% confidence (which happens surprisingly often).
If you are not going to be able to call winners at 3% lift, then you are going to have a lot fewer winners and will have to focus on things that have higher betas like real estate over smaller content or cosmetic changes.
Other Tools
Test Tracking Sheet
I do all analysis in a simple Excel spreadsheet that I share via Google Drive. I have leveraged other mediums, and I have used other sharing tools, but ultimately the goal here is that you should have clean tracking and have it accessible to other parties. The tool needs to show performance, estimated impact, and most importantly the cumulative graphical outcome. Another key value of using an external spreadsheet is that you can use it combine distinct actions into a cumulative revenue if that is required for your organization.
You should keep a record (screenshot) of what each variant looks like as part of this document. I also do a survey of my common test group for what they think will be the outcomes, and keep that as a tab as part of this document so that we have a record of the total votes to see how often we are right, which is almost never.
Program Tracking Resource
You should have an easy repository of all tests that have run as well as your future roadmap in a commonly accessible location. I currently use a wiki for this but have also used another shared spreadsheet and/or a project management tool to accomplish this.
The key here is that people should never have to ask what was run, where, or what the impact was. They should be able to see all past experiences and be able to get a good idea of when something ran as well as when things in the future might run (all roadmaps have to be extremely flexible as you build them around resource instead of get resources to meet your roadmap).
A dedicated tool for test documentation is in private beta right now, but should be launched soon.
Rules of Action
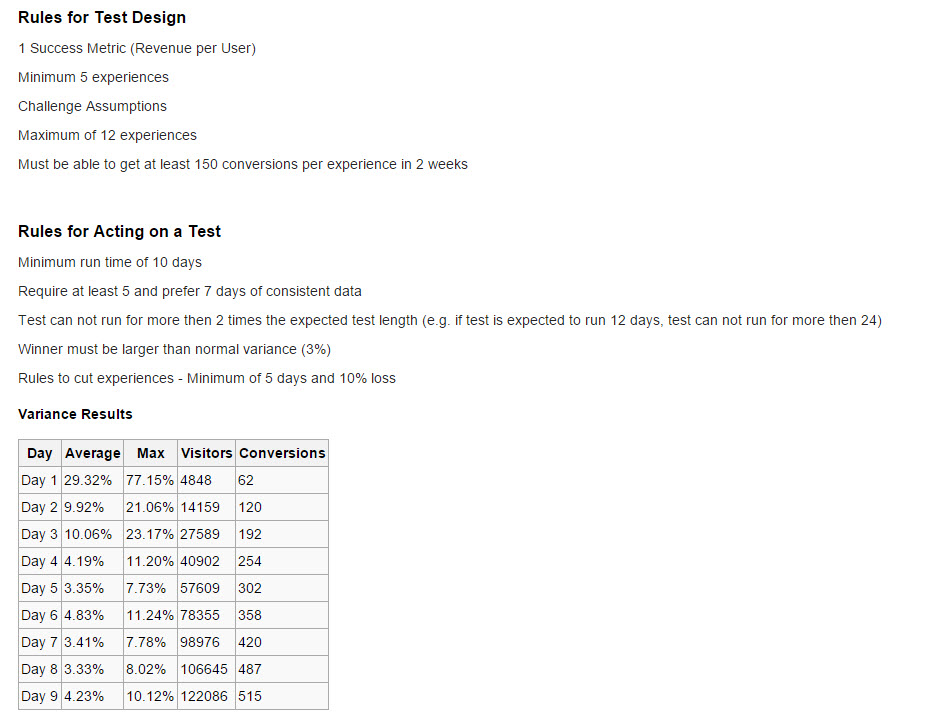
It is important to have an agreed on and available document that expresses how you are going to act on a test. Having people agree on this outside of a specific test and making this an easy to access resource greatly reduces headaches down the line. This doesn’t have to be complicated but it should cover: what is necessary for a test to be called, what will happen when it is called, how and when you will kill lower performing experiences, the results of your variance studies, and what is required for a test to be run in the first place.
One of the great benefits of the creation of this document is that it helps you make people aware of these things and help them know what you will be doing, even if they are not directly involved. Even if this is just another page on your wiki having it as a separate item is of great value and is often overlooked.
Here’s what it can look like (I have seen it done like 10 different ways):
Living Knowledge Base
By far the most valuable thing you will have from a successful program are the lessons you have learned from your testing. What does matter, what doesn’t, where you were right and most importantly where you were wrong. While it is very easy to take too much away from a single test, things you see consistently are a gold mine as they will allow you to avoid fruitless conversations and focus resources on things that do matter going forward. Because of this it is vital that you have a constantly shifting and living resource that everyone has access to, not just your normal testing group.
You can either use the same medium as your other tracking or make another more accessible medium. Wikis again work great for this especially if they are part of your larger organizations intranet. Making this information available to everyone and constantly reminding or pointing people to it will also greatly improve the visibility and reach of your program. Nothing gets people to buy into testing like consistent and meaningful results.
Conclusion
There are a lot of things that go into a successful program. Having the right mindset is the most important, but secondly are tools that reinforce good behaviors and make your life easier. While individual tools ultimately are fungible, the needed outcomes are not. Too many programs think that just having a testing tool is the same as having an optimization program. Few also put all the other pieces in place to allow everything to run at full speed.
Just like with a test success and failure is determined before you launch a test, not after. Doing the necessary groundwork to have the tools you need and leveraging them in the right way can greatly improve a program. Avoiding a tool or taking an easy way out can hinder a program much later down the line. It requires discipline to suffer the small amount of pain upfront and get all your ducks in a row before you get too caught up in specific tests.
“Men have become the tools of their tools.” – Henry David Thoreau
Related Posts
-

"Our A/B testing tool's visual editor allows marketers to set up tests without needing developers!" A version…
-

Are you in B2B / lead gen? Qualifying leads a challenge? There's a new (non-enterprise)…
-
Both your visitor and Google prefer your site to be fast. Increasing site speed has…
-
Marketers of all stripes are obsessed with tools. This obsession has bred comprehensive lists of…

Great article and very informative! Good to think about the entire testing strategy instead of just focusing on a single test hoping for a home run.
Hi Andrew: great post and all good points that I agree with. I just had a quick clarifying question on your point quoted below:
“A second dimension of data is how the tool purports to tell you when you can act on a test. To put this simply, ignore all of it as there is not a tool out there that does a good job and that does not overly rely on rough statistical measures to express confidence. There are minor improvements from a single tail to a two tail to Bayesian or Monte Carlo types of evaluations but even in the best case they are functionally not enough to ever tell you when a test is done.”
Do you mean:
1) the statistical significance metrics given by most tools are approximative but still usable IF not used as an indication to stop a test and coupled with additional metrics like the minimum sample size required, business cycles, etc…
OR
2) the statistical significance metrics given by most tools are rubbish and should not be used at all?
I would really be interested in knowing exactly what you meant there.
My personal opinion is actually depending on the metrics measured as the goal of the test:
Metrics such as global site-wide conversion rate: I am leaning towards 1
Metrics such as revenue (e.g. a variation increases average order value by 10%): I am leaning strongly towards 2. Most tools do not calculate their statistical significance measure with a correct a test. The simplest usable one that come to mind is the Mann-Whitney U test (http://en.wikipedia.org/wiki/Mann%E2%80%93Whitney_U_test), but most tools use either T-test, Z-test, Chi squared, F-test, etc. that should not be used with an AOV distribution (non normal, not fitted, etc.).
Julian,
I hope to write more in depth on this in the future but you nailed both meanings I had with that statement. In the absolute best case scenario the confidence measures use still suffer from selection bias, constrained outcomes, non-normal distribution, variance and just a whole slew of other problems. Essentially it is a very imperfect measure that also suffers from a lot of flawed assumptions. Even worse people confuse statistical confidence with colloquial confidence and act irrationally on that information.
In the worst case scenarios the data is completely misleading and leads to a false belief in hard statistical measures that most likely do not match the required assumptions and that lead to a large number of type I errors. This is especially true for non-binary evaluations such as RPV. Even worse are tools that measure the sum of R2 on the order values which means they are calculating confidence on AOV but not on true RPV, which would require much more processing power and constantly redoing the entire function.
In all cases following the confidence measures is extremely troublesome. In the best case they need a whole slew of other things on top of them (though just measured sample size suffers from a whole slew of sampling biases) that are needed to make them functional. In the worst case, especially for sites with large variance, which again is not population error rate, they are completely false and misleading.
I would argue that for people starting out they are better using other proxy measures instead of confidence and ignoring it completely. For those situations where it makes sense you can use any of the various statistical measures in context with other forms of validation for the inherent assumptions. In all cases it is at best just a small part of a much larger more complex puzzle.
Great article, very helpful.
Regarding segmentation, one issue I have encountered is this:
– For post-test segmented analysis, Google Analytics is a strong option based on the post you’ve linked above (which also was very useful):
https://cxl.com/analyze-ab-test-results-google-analytics/
– However, from my understanding, Google Content Experiments does not allow you to segment the visitors who will view your test.
Therefore, it seems that you need an Optimizely/VWO/similar so you can segment who sees your test (e.g. only new visitors), whilst you need to integrate this to Google Analytics in order to perform full segmentation analysis (which is required from my perspective e.g. if I want to track behaviour beyond the test page itself).
Could you or a reader please confirm if this understanding is correct?
It just seems strange that either a) Google haven’t developed GTE to allow for segmenting visitors who see your tests (as, it is not particular useful to view results by segment using GA, if you can’t then continue further tests to an individual segment using GTE) b) Optimizely/VWO haven’t built some form of reverse feed, whereby Google data is feed back into their platform to allow the analysis you need.
Many thanks for any replies.
With Content Experiments you can’t target a specific segment, but you can analyze the results across segments. But you can’t really complain about Content Experiments as it’s free :)
With VWO, Optimizely and other tools like Adobe Target, Qubit etc you can run an experiment targeting a specific segment.
The benefit of doing post-test analysis in Google Analytics is that you can see how the variations performed across multiple metrics. Let’s say your revenue per visitor increased for treatment B. Why? In GA you can see avg quantity, avg order value and which products they bought – rich information that will lead to rich insights.
I recommend using Optimizely and VWO for testing only, and use GA for post-test analysis.
Hi Peep,
Great thanks for your reply, hoping to get much of the advice not only on this blog post but on many others live on our site in the coming weeks.
On a side note, I am 90%+ going for a 28 hour round flight to attend Conversion Live given how awesome your blog is :)
Very nice article. But it’s only the first quarter of the article because your experience in using the tools is only hinted at. Of course, your expertience is subjective but it would give a very good starting point.
Why do you consider heatmaps pointless?
Beatrix,
Quick background: doing testing in various forms for 12 years, half of which was consulting where I have worked with over 300 different companies including 15 of the top 200 websites out there. Specifically my role was as the guy who would come in and turn around programs after they had run aground or were seeing no or limited value from following a lot of the actions that most tool vendors and some consultants put out there. I started using Offermatica (Test&Target and now Target) at version 12 (they are well above 100 now). Currently use Optimizely, have used Google Experiments, Conductrics (which I should have mentioned as that is a tool that is on the uptick) as well as built or leveraged many different internal tools. I have also worked with clients and consulted on Monetate, VWO, and other home brew tools as well as a few tools that are no longer around.
The point I was trying to make with this article was that way too much time is thought that a tool solves problems when in reality the tool is a small cog in a much larger picture of how you think about testing and optimization. It comes down to this: do you use testing as a means to validate preconceived ideas or people’s opinions? If so then any tool you use is going to have the same flawed limited impact. If you are thinking about testing and optimization as a unique and powerful discipline and leverage tools to enable that then you are always going to get value but the differences in the tools can change what and where you focus.
As far as heatmaps and really any click measuring the problem here is that there is no mathematical way to attribute correlation or causation from a single data point but due to human biases people will consistently do so, resulting in flawed and biased decisions which hold no functional utility and whose only possible outcome is to direct attention away from what the data is actually telling you. This is a much larger issue but if you want more of my thoughts on it:
http://testingdiscipline.com/2013/05/20/how-you-can-stop-statistics-from-taking-advantage-of-you-part-1/
http://testingdiscipline.com/2012/07/25/7-deadly-sins-of-testing-confusing-rate-and-value/
Man, Peep, you always bring in the best people ! I always saw Andrew’s blog as some kind of little know gem of rigorous testing discipline, and it’s only fair that he got more exposure here.
Previous articles were great, looking forward to the next one. This is real CRO connoisseur stuff. :)
Thanks :) Andrew knows his shit
Andrew,
I noticed in your background you didn’t mention experience with SiteSpect. I would love to have you check us out when you have time.
We definitely agree on a lot of what you said for testing. Speed is especially critical. When clients come to SiteSpect, it’s usually because they have run into issues related to speed. Either they want to run more tests per year and spend less time creating them or they have major issues with the latency and/or flicker caused by JavaScript tags.
The speed that you refer to seems to really be around WYSIWYG editor testing. While this is certainly important (and because it’s important, we added a visual editor last year), chances are the tests you really want to run are too complex for a WYSIWYG tool. For other tools, this means writing lots of JavaScript, which can take a long time. This is why companies like Walmart and Target use SiteSpect. They want to run a LOT of experiments and test the entire experience.
Great post… when you say aim for 5 experiences, are you suggesting running a test with 5 variations? Seems like a tough rule to follow for smaller websites out there with less than 100k monthly uniques. For lower traffic sites I usually suggest aiming for 2-3 variations max, unless you’re either 1) aiming for huge lifts of 30-50% or higher, or 2) comfortable waiting a really long time for results. Curious to hear your thinking here…
Mike,
You are right that this and just about all of my suggestions are aimed more for the situation of a site that is getting at least 500 conversions a month. It is at this point that you can really run a optimization program instead of just testing. There are many different tactics you can and should take when you are working with fewer conversions, but keep in mind that in those cases it is even more important to get consistent results, not less, which means pushing the limit and going with more options and going past your biases is actually far more important as you can not miss an opportunity and need to bat 100%, not the 14% which is the industry average.
For sites that are on the threshold or higher it is also important to remember that there is a huge difference between running a test and running a successful optimization program. Just because you know how to drive a car doesn’t mean you should be driving in F1.
Running a test is probably the second least important part of an optimization program with the only thing less important are the test ideas which are almost completely fungible. It is just a means to an end, not the end in and of itself. Only once you are really trying to do the right things and really drive a program do the differences in tools really start to matter.
You can see a bit more about my thoughts on the things that are important to a successful program in my previous post here: https://cxl.com/the-psychology-of-a-successful-testing-program/
As well as things that are commonly missed when people confuse one running a test or two for an optimization program here: http://testingdiscipline.com/2013/09/09/one-problem-but-many-voices-the-one-thing-people-need-to-understand-about-optimization/
Do you have a complete beginners guide? We have a new intern and ideally need her to learn about conversion.
Start reading everything on this blog :)
http://www.amazon.com/Master-Essentials-Conversion-Optimization-Approach-ebook/dp/B00SGDKE3Q/
https://cxl.com/how-to-build-a-strong-ab-testing-plan-that-gets-results/
I find it interesting that you are leaving an intern to handle what should be, with even the smallest level of competence the number one driver of revenue for your organization. It is also something that when done wrong will just be a series of tests that are used to validate opinions and to keep propagating the same tired and damaging “best practices”. It would seem to be a misplaced allocation of resources. Whats more the level of sophistication and the knowledge level of so many disparate disciplines and cross functional knowledge needed to do optimization correctly would dictate that you need your most skilled, not your least skilled people on optimization.
Hiring or focusing resources towards someone who knows what they are doing (instead of pretending to) should surpass all other profit efforts by magnitudes within a short period of time. No offense to the many talented and hard working people in the many other disciplines, but you can put an intern on social, email, SEO, or even SEM with little real impact, but not taking optimization as a core discipline really means that you will get little or even negative value from your efforts.
This is really great for those developers who are starting to learn more about conversions. I just want to know if you do have tools to improve website speed too? Thanks and appreciate it if you do. Great article by the way!