
When should you use bandit tests, and when is A/B/n testing best?
Though there are some strong proponents (and opponents) of bandit testing, there are certain use cases where bandit testing may be optimal. Question is, when?
First, let’s dive into bandit testing and talk a bit about the history of the N-armed bandit problem.
Table of contents
What is the multi-armed bandit problem?
The multi-armed bandit problem is a classic thought experiment, with a situation where a fixed, finite amount of resources must be divided between conflicting (alternative) options in order to maximize each party’s expected gain.
Imagine this scenario:
You’re in a casino. There are many different slot machines (known as ‘one-armed bandits,’ as they’re known for robbing you), each with a lever (and arm, if you will). You think that some slot machines payout more frequently than others do, so you’d like to maximize this.
You only have a limited amount of resources—if you pull one arm, then you’re not pulling another arm. Of course, the goal is to walk out of the casino with the most money. Question is, how do you learn which slot machine is the best and get the most money in the shortest amount of time?
If you knew which lever would pay out the most, you would just pull that lever all day. In regards to optimization, the applications of this problem are obvious. As Andrew Anderson said in an Adobe article:

Andrew Anderson:
“In an ideal world, you would already know all possible values, be able to intrinsically call the value of each action, and then apply all your resources towards that one action that causes you the greatest return (a greedy action). Unfortunately, that is not the world we live in, and the problem lies when we allow ourselves that delusion. The problem is that we do not know the value of each outcome, and as such need to maximize our ability of that discovery.”
What is bandit testing?
Bandit testing is a testing approach that uses algorithms to optimize your conversion target while the experiment is still running rather than after it has finished.
The practical differences between A/B testing and bandit testing
A/B split testing is the current default for optimization, and you know what it looks like:

You send 50% of your traffic to the control and 50% of your traffic to variation, run the test ‘til it’s valid, and then decide whether to implement the winning variation.
Explore-exploit
In statistical terms, A/B testing consists of a short period of pure exploration, where you’re randomly assigning equal numbers of users to Version A and Version B. It then jumps into a long period of pure exploitation, where you send 100% of your users to the more successful version of your site.
In Bandit Algorithms for Website Optimization, the author outlines two problems with this:
- It jumps discretely from exploration to exploitation, when you might be able to transition more smoothly.
- During the exploratory phase (the test), it wastes resources exploring inferior options in order to gather as much data as possible.
In essence, the difference between bandit testing and a/b/n testing is how they deal with the explore-exploit dilemma.
As I mentioned, A/B testing explores first then exploits (keeps only winner).
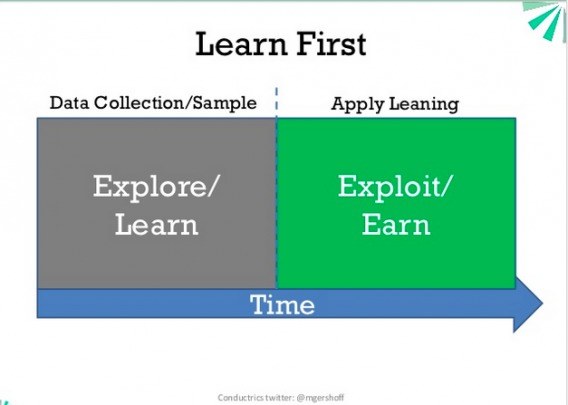
Bandit testing tries to solve the explore-exploit problem in a different way. Instead of two distinct periods of pure exploration and pure exploitation, bandit tests are adaptive, and simultaneously include exploration and exploitation.

So, bandit algorithms try to minimize opportunity costs and minimize regret (the difference between your actual payoff and the payoff you would have collected had you played the optimal—best—options at every opportunity). Matt Gershoff from Conductrics wrote a great blog post discussing bandits. Here’s what he had to say:

Matt Gershoff:
“Some like to call it earning while learning. You need to both learn in order to figure out what works and what doesn’t, but to earn; you take advantage of what you have learned. This is what I really like about the Bandit way of looking at the problem, it highlights that collecting data has a real cost, in terms of opportunities lost.”
Chris Stucchio from VWO offers the following explanation of bandits:

Chris Stucchio:
“Anytime you are faced with the problem of both exploring and exploiting a search space, you have a bandit problem. Any method of solving that problem is a bandit algorithm—this includes A/B testing. The goal in any bandit problem is to avoid sending traffic to the lower performing variations. Virtually every bandit algorithm you read about on the internet (primary exceptions being adversarial bandit, my jacobi diffusion bandit, and some jump process bandits) makes several mathematical assumptions:
a) Conversion rates don’t change over time.
b) Displaying a variation and observing a conversion happen instantaneously. This means the following timeline is impossible: 12:00 Visitor A sees Variation 1. 12:01 visitor B sees Variation 2. 12:02 Visitor A converts.
c) Samples in the bandit algorithm are independent of each other.
A/B testing is a fairly robust algorithm when these assumptions are violated. A/B testing doesn’t care much if conversion rates change over the test period, i.e. if Monday is different from Saturday, just make sure your test has the same number of Mondays and Saturdays and you are fine. Similarly, as long as your test period is long enough to capture conversions, again—it’s all good.”
In essence, there shouldn’t be an ‘A/B testing vs. bandit testing, which is better?’ debate, because it’s comparing apples to oranges. These two methodologies serve two different needs.
Benefits of bandit testing
The first question to answer, before answering when to use bandit tests, is why to use bandit tests. What are the advantages?
When they were still available (prior to August 2019), Google Content Experiments used bandit algorithms. They used to reason that the benefits of bandits are plentiful:
They’re more efficient because they move traffic towards winning variations gradually, instead of forcing you to wait for a “final answer” at the end of an experiment. They’re faster because samples that would have gone to obviously inferior variations can be assigned to potential winners. The extra data collected on the high-performing variations can help separate the “good” arms from the “best” ones more quickly.
Matt Gershoff outlined 3 reasons you should care about bandits in a post on his company blog (paraphrased):
- Earn while you learn. Data collection is a cost, and bandit approach at least lets us consider these costs while running optimization projects.
- Automation. Bandits are the natural way to automate the selection optimization with machine learning, especially when applying user target—since correct A/B tests are much more complicated in that situation.
- A changing world. Matt explains that by letting the bandit method always leave some chance to select the poorer performing option, you give it a chance to ‘reconsider’ the option effectiveness. It provides a working framework for swapping out low performing options with fresh options, in a continuous process.
In essence, people like bandit algorithms because of the smooth transition between exploration and exploitation, the speed, and the automation.
A few flavors of bandit methodology
There are tons of different bandit methods. Like a lot of debates around testing, a lot of this is of secondary importance—misses the forest for the trees.
Without getting too caught up in the nuances between methods, I’ll explain the simplest (and most common) method: the epsilon-greedy algorithm. Knowing this will allow you to understand the broad strokes of what bandit algorithms are.
Epsilon-greedy method
One strategy that has been shown to perform well time after time in practical problems is the epsilon-greedy method. We always keep track of the number of pulls of the lever and the amount of rewards we have received from that lever. 10% of the time, we choose a lever at random. The other 90% of the time, we choose the lever that has the highest expectation of rewards. (source)
Okay, so what do I mean by greedy? In computer science, a greedy algorithm is one that always takes the action that seems best at that moment. So, an epsilon-greedy algorithm is almost a fully greedy algorithm—most of the time it picks the option that makes sense at that moment.
However, every once in a while, an epsilon-greedy algorithm chooses to explore the other available options.
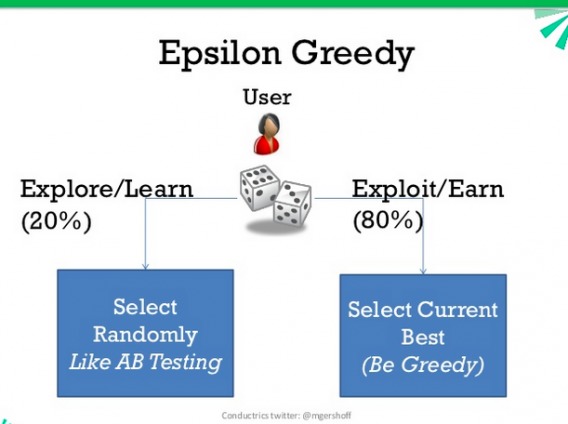
So epsilon-greedy is a constant play between:
- Explore: randomly select action certain percent of time (say 20%);
- Exploit (play greedy): pick the current best percent of time (say 80%).
This image (and the article from which it came) explains epsilon-greedy really well:
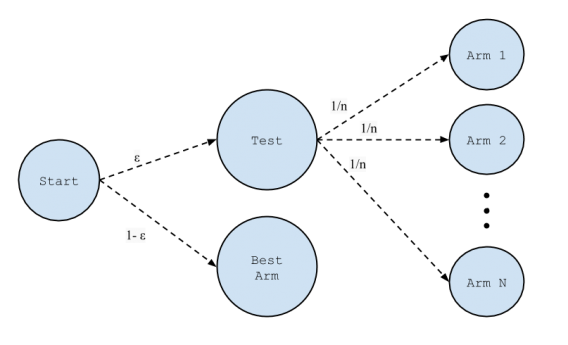
There are some pros and cons to the epsilon-greedy method. Pros include:
- It’s simple and easy to implement.
- It’s usually effective.
- It’s not as affected by seasonality.
Some cons:
- It doesn’t use a measure of variance.
- Should you decrease exploration over time?
What about other algorithms?
Like I said, a bunch of other bandit methods try to solve these cons in different ways. Here are a few:
Could write 15,000 words on this, but instead, just know the bottom line is that all the other methods are simply trying to best balance exploration (learning) with exploitation (taking action based on current best information).
Matt Gershoff sums it up really well:
Matt Gershoff:
“Unfortunately, like the Bayesian vs Frequentist arguments in AB testing, it looks like this is another area where the analytics community might get lead astray into losing the forest for the trees. At Conductrics, we employ and test several different bandit approaches. In the digital environment, we want to ensure that whatever approach is used, that it is robust to nonstationary data. That means that even if we use Thompson sampling, a UCB method, or Boltzmann approach, we always like to blend in a bit of the epsilon-greedy approach, to ensure that the system doesn’t early converge to a sub-optimal solution. By selecting a random subset, we also are able to use this data to run a meta A/B Test, that lets the client see the lift associated with using bandits + targeting.”
Note: if you want to nerd out on the different bandit algorithms, this is a good paper to check out.
When to use bandit tests instead of A/B/n tests?
There’s a high level answer, and then there are some specific circumstances in which bandit works well. For the high level answer, if you have a research question where you want to understand the effect of a treatment and have some certainty around your estimates, a standard A/B test experiment will be best.
According to Matt Gershoff, “If on the other hand, you actually care about optimization, rather than understanding, bandits are often the way to go.”
Specifically, bandit algorithms tend to work well for really short tests—and paradoxically—really long tests (ongoing tests). I’ll split up the use cases into those two groups.
1. Short tests
Bandit algorithms are conducive for short tests for clear reasons—if you were to run a classic A/B test instead, you’d not even be able to enjoy the period of pure exploitation (after the experiment ended). Instead, bandit algorithms allow you to adjust in real time and send more traffic, more quickly, to the better variation. As Chris Stucchio says, “Whenever you have a small amount of time for both exploration and exploitation, use a bandit algorithm.”
Here are specific use cases within short tests:
a. Headlines
Headlines are the perfect use case for bandit algorithms. Why would you run a classic A/B test on a headline if, by the time you learn which variation is best, the time where the answer is applicable is over? News has a short half-life, and bandit algorithms determine quickly which is the better headline.
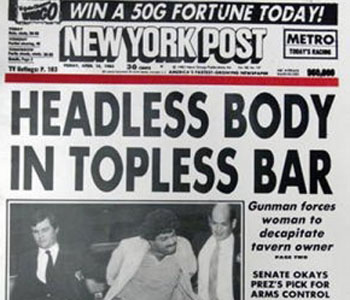
Chris Stucchio used a similar example on his Bayesian Bandits post. Imagine you’re a newspaper editor. It’s not a slow day; a murder victim has been found. Your reporter has to decide between two headlines, “Murder victim found in adult entertainment venue” and “Headless Body in Topless Bar.” As Chris says, geeks now rule the world—this is now usually an algorithmic decision, not an editorial one. (Also, this is probably how sites like Upworthy and BuzzFeed do it).
b. Short term campaigns and promotions
Similar to headlines, there’s a big opportunity cost if you choose to A/B test. If your campaign is a week long, you don’t want to spend the week exploring with 50% of your traffic, because once you learn anything, it’s too late to exploit the best option.
This is especially true with holidays and seasonal promotions. Stephen Pavlovich from Conversion.com recommends bandits for short term campaigns:

Stephen Pavlovich:
“A/B testing isn’t that useful for short-term campaigns. If you’re running tests on an ecommerce site for Black Friday, an A/B test isn’t that practical—you might only be confident in the result at the end of the day. Instead, a MAB will drive more traffic to the better-performing variation—and that in turn can increase revenue.”
2. Long-term testing
Oddly enough, bandit algorithms are effective in long term (or ongoing) testing. As Stephen Pavlovich put it:
Stephen Pavlovich:
“A/B tests also fall short for ongoing tests—in particular, where the test is constantly evolving. Suppose you’re running a news site, and you want to determine the best order to display the top five sports stories in. A MAB framework can allow you to set it and forget. In fact, Yahoo! actually published a paper on how they used MAB for content recommendation, back in 2009.”
There are a few different use cases within ongoing testing as well:
a. “Set it and forget it” (automation for scale)
Because bandits automatically shift traffic to higher performing (at the time) variations, you have a low-risk solution for continuous optimization. Here’s how Matt Gershoff put it:
Matt Gershoff:
“Bandits can be used for ‘automation for scale.’ Say you have many components to continuously optimize, the bandit approach gives you a framework to partially automate the optimization process for low risk, high transaction problems that are too costly to have expensive analysts pour over”
Ton Wesseling also mentions that bandits can be great for testing on high traffic pages after learning from A/B tests:

Ton Wesseling:
“Just give some variations to a bandit and let it run. Preferable you use a contextual bandit. We all know the perfect page for everyone does not exist, it differs per segment. The bandit will show the best possible variation to each segment.”
b. Targeting
Another long term use of bandit algorithms is targeting—which is specifically pertinent when it comes to serving specific ads and content to user sets. As Matt Gershoff put it:
Matt Gershoff:
“Really, true optimization is more of an assignment problem than a testing problem. We want to learn the rules that assign the best experiences to each customer. We can solve this using what is known as a contextual bandit (or, alternatively, a reinforcement learning agent with function approximation). The bandit is useful here because some types of users may be more common than others. The bandit can take advantage of this, by applying the learned targeting rules sooner for more common users, while continuing to learn (experiment) on the rules for the less common user types.”
Ton also mentioned that you can learn from contextual bandits:
Ton Wesseling:
“By putting your A/B test in a contextual bandit with segments you got from data research, you will find out if certain content is important for certain segments and not for others. That’s very valuable—you can use these insights to optimize the customer journey for every segment. This can be done with looking into segments after an A/B test too, but it’s less time consuming to let the bandit do the work.”
Further reading: A Contextual-Bandit Approach to Personalized News Article Recommendation
c. Blending Optimization with Attribution
Finally, bandits can be used to optimize problems across multiple touch points. This communication between bandits ensures that they’re working together to optimize the global problem and maximize results. Matt Gershoff gives the following example:
Matt Gershoff:
“You can think of Reinforcement Learning as multiple bandit problems that communicate with each other to ensure that they are all working together to find the best combinations across all of the touch points. For example, we have had clients that placed a product offer bandit on their site’s home page and one in their call center’s automated phone system. Based on the sales conversions at the call center, both bandits communicated local results to ensure that they are working in harmony optimize the global problem.”
Caveats: potential drawbacks of bandit testing
Even though there are tons of blog posts with slightly sensationalist titles, there are a few things to consider before jumping on the bandit bandwagon.
First, multi-armed-bandits can be difficult to implement. As Shana Carp said on a Growthhackers.com thread:
MAB is much much more computationally difficult to pull off unless you know what you are doing. The functional cost of doing it is basically the cost of three engineers—a data scientist, one normal guy to put into code and scale the code of what the data scientist says, and one dev-ops person. (Though the last two could probably play double on your team.) It is really rare to find data scientists who program extremely well.
The second thing, though I’m not sure it’s a big issue, is the time it takes to reach significance. As Paras Chopra pointed out, “There’s an inverse relationship (and hence a tradeoff) between how soon you see statistical significance and average conversion rate during the campaign.”
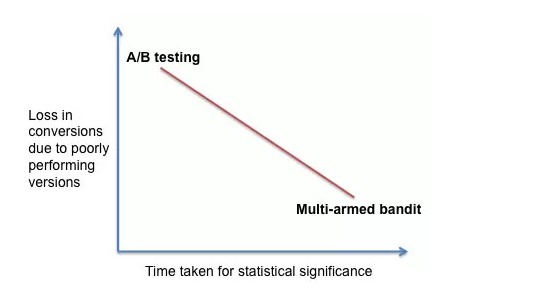
Chris Stucchio also outlined what he called the Saturday/Tuesday problem. Basically, imagine you’re running a test on two headlines:
- Happy Monday! Click here to buy now.
- What a beautiful day! Click here to buy now.
Then suppose you run a bandit algorithm, starting on Monday:
- Monday: 1,000 displays for “Happy Monday,” 200 conversions. 1,000 displays for “Beautiful Day,” 100 conversions.
- Tuesday: 1,900 displays for “Happy Monday,” 100 conversions. 100 displays for “Beautiful Day,” 10 conversions.
- Wednesday: 1,900 displays for “Happy Monday,” 100 conversions. 100 displays for “Beautiful Day,” 10 conversions.
- Thursday: 1,900 displays for “Happy Monday,” 100 conversions. 100 displays for “Beautiful Day,” 10 conversions.
Even though “Happy Monday” is inferior (20% conversion rate on Monday and 5% rest of the week = 7.1% conversion rate), the bandit algorithm has almost converged to “Happy Monday, ” so the samples shown “Beautiful Day” is very low. It takes a lot of data to correct this.
(Note: A/B/n tests have the same problem non-stationary data. That’s why you should test for full weeks.)
Chris also mentioned that bandits shouldn’t be used for email blasts:
Chris Stucchio:
“One very important note—email blasts are a fairly poor use case for standard bandits. The problem is that with email, conversions can happen long after a display occurs—you might send out thousands of emails before you see the first conversion. This violates the assumption underlying most bandit algorithms.”
Conclusion
Andrew Anderson summed it up really well in a Quora answer:
Andrew Anderson:
“In general bandit-ased optimization can produce far superior results to regular A/B testing, but it also highlights organizational problems more. You are handing over all decision making to a system. A system is only as strong as its weakest points and the weakest points are going to be the biases that dictate the inputs to the system and the inability to understand or hand over all decision making to the system. If your organization can handle this then it is a great move, but if it can’t, then you are more likely to cause more problems then they are worse. Like any good tool, you use it for the situations where it can provide the most value, and not in ones where it doesn’t. Both techniques have their place and over reliance on any one leads to massive limits in the outcome generated to your organization.”
As mentioned above, the situations where bandit testing seems to flourish are:
- Headlines and short-term campaigns;
- Automation for scale;
- Targeting;
- Blending optimization with attribution.
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

When should you use multivariate testing, and when is A/B/n testing best? The answer is…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-
Just when you start to think that A/B testing is fairly straightforward, you run into…
-
One-tailed tests allow for the possibility of an effect in one direction. Two-tailed tests test…




{kind=link}
Awesome, awesome, awesome post. Way to go deep and explain the difference between a/b testing and multi arm bandit. Especially, when to use which one. This is exactly why at AdNgin our testing platform runs on a multi arm bandit algorithm.
Hey Alex,
I am yet to see any test that will ‘beat’ the A/B Tests. The bandit test is new to me but I will still prefer to use A/B tests for its simplicity and applicability.
I guess there must be a real way to apply the bandit. It sure must be dependent on the organization!
I left this comment in kingged.com as well
It’s not AB tests vs bandit, it’s when bandit is a better option. For example using A/B testing for a holiday promotion campaign is typically not a good idea, but bandit is.
Hey Alex,
You smashed it with this one. To tell the truth, I had fuzzy concept of bandit tests and their uses before reading. But you’ve cleared things up a ton and have done a great job of breaking the concept down.
Thanks man!
Thanks, Hassan!
Bandit testing, this kind of test involves a statistical problem set-up. It is proven and tested. When you’re running a certain campaign in your business and you only have limited resources just like money and time, this is the best.
Bandit test is a must try useful in minimizing opportunity costs and minimizing regret. While the A/b testing involves taking 2 or more variants and there are drawbacks like deciding how many times you will try the test and you could lose large number of conversions by doing so.
All in all, the tests are great, but one should decide. These tests will help us depending on the needs, answers and the data that a marketer wants to know.
Great article! One of the best for months :)
Great article Alex! We’ve developed our own optimization service that incorporates bandit algorithms. Our main focus is helping eCommerce companies to optimize more challenging, data driven opportunities where normal A/B testing isn’t appropriate. We’re offering free trial account to use our API based service so people can see how easy it is to use machine learning in their own applications. Sign up at http://www.incisive.ly